Data Practicing-EP0
Before You Read This
该文只是一门课程数据挖掘的大作业记录文, 并不是教程式文章.
Why This Topic?
看了很多人写的技术博客, 发现许多都是基于Pseudo-Distributed Mode或者Fully-Distributed Mode. 这两种模式因为资源问题我也只成功搭建并使用过前者, 当时在Windows10上拖着一个CentOS8的虚拟机, 因为数据集就快2GB大小, 一套下来发现虚拟机吃的内存快接近7G.
又想试试YARN又不想做多机分布式, 那就做单机YARN 关于YARN:官方的也很简明易懂 Apache Hadoop YARN
毕竟数据集只是几G, python直接上pandas套装估计会更方便.
抱着入门一下这个技术栈, 完成一下大作业和想拥抱一下Arch社区的心态, 在使用过LinuxMint和Fedora的我换到了Manjaro Linux 20.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
mijazz@lenovo ~ screenfetch
██████████████████ ████████ mijazz@lenovo
██████████████████ ████████ OS: Manjaro 20.2 Nibia
██████████████████ ████████ Kernel: x86_64 Linux 5.8.18-1-MANJARO
██████████████████ ████████ Uptime: 16m
████████ ████████ Packages: 1239
████████ ████████ ████████ Shell: zsh 5.8
████████ ████████ ████████ Resolution: 1920x1080
████████ ████████ ████████ DE: KDE 5.76.0 / Plasma 5.20.3
████████ ████████ ████████ WM: KWin
████████ ████████ ████████ GTK Theme: Breath [GTK2/3]
████████ ████████ ████████ Icon Theme: breath2-dark
████████ ████████ ████████ Disk: 18G / 102G (19%)
████████ ████████ ████████ CPU: Intel Core i5-7300HQ @ 4x 3.5GHz [45.0°C]
████████ ████████ ████████ GPU: GeForce GTX 1050
RAM: 2880MiB / 15904MiB
mijazz@lenovo ~ uname -a
Linux lenovo 5.8.18-1-MANJARO #1 SMP PREEMPT Sun Nov 1 14:10:04 UTC 2020 x86_64 GNU/Linux
Prerequisite
Java - OpenJDK8
为了避免奇怪的兼容性问题, 根据
Hadoop官方的wiki, 其推荐版本是8, 并且更高版本的Hadoop支持11. 同时明确指明了OpenJDK8是官方用于其编译的版本. 此处参考: cwiki-Apache这里给出
AdoptOpenJDK8的地址Redhat的, OpenJDK自编译的, 又或者来自
Pacman包管理的都应该不成问题.但是我在
CentOS8上首次尝试Hadoop的时候,conf里也要多配置一次$JAVA_HOME有点奇怪Hadoop - Hadoop 3.1.4 Tarball
Spark - Spark 2.4.7 Tarball
选
Pre-built with user-provided Apache Hadoop因采用YARN部署
Prepare Environment
Extract JDK
1
2
3
4
5
6
7
8
9
10
11
12
13
14
mijazz@lenovo ~/devEnvs ll -a
total 100M
drwxr-xr-x 6 mijazz mijazz 4.0K Nov 25 15:23 .
drwx------ 36 mijazz mijazz 4.0K Nov 25 15:24 ..
-rw-r--r-- 1 mijazz mijazz 100M Nov 24 15:20 OpenJDK8U-jdk_x64_linux_hotspot_8u275b01.tar.gz
mijazz@lenovo ~/devEnvs tar -xf ./OpenJDK8U*.tar.gz
mijazz@lenovo ~/devEnvs mv ./jdk8u275-b01 ./OpenJDK8
mijazz@lenovo ~/devEnvs rm ./OpenJDK8U*.tar.gz
mijazz@lenovo ~/devEnvs ll -a
total 28K
drwxr-xr-x 7 mijazz mijazz 4.0K Nov 25 15:28 .
drwx------ 36 mijazz mijazz 4.0K Nov 25 15:28 ..
drwxr-xr-x 8 mijazz mijazz 4.0K Nov 9 20:23 OpenJDK8
Configure $PATH
我使用的是
zsh, 并且不索引bashrc. 虽然到时候我会在主shell里启动, 但是不保证他会不会在某些部件里调用bash.我就把环境变量同时加进
~/.bashrc和~/.zshrc里了.如果你是使用
bash, 只需加进~/.bashrc, 记得source或重启shell生效.
1
2
3
4
5
6
7
8
9
10
11
echo '# Java Environment Variable' >> ~/.bashrc
echo 'export JAVA_HOME="/home/mijazz/devEnvs/OpenJDK8"' >> ~/.bashrc
echo 'export JRE_HOME="${JAVA_HOME}/jre"' >> ~/.bashrc
echo 'export CLASSPATH=".:${JAVA_HOME}/lib:${JRE_HOME}/lib"' >> ~/.bashrc
echo 'export PATH="${JAVA_HOME}/bin:$PATH"' >> ~/.bashrc
# Only if u r using zsh
echo '# Java Environment Variable' >> ~/.zshrc
echo 'export JAVA_HOME="/home/mijazz/devEnvs/OpenJDK8"' >> ~/.zshrc
echo 'export JRE_HOME="${JAVA_HOME}/jre"' >> ~/.zshrc
echo 'export CLASSPATH=".:${JAVA_HOME}/lib:${JRE_HOME}/lib"' >> ~/.zshrc
echo 'export PATH="${JAVA_HOME}/bin:$PATH"' >> ~/.zshrc
Verify Configuration
1
2
3
4
5
6
mijazz@lenovo ~ echo $JAVA_HOME
/home/mijazz/devEnvs/OpenJDK8
mijazz@lenovo ~ java -version
openjdk version "1.8.0_275"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_275-b01)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.275-b01, mixed mode)
SSH, sshd.service
Hadoop: Setting up a Single Node Cluster.
ssh must be installed and sshd must be running to use the Hadoop scripts that manage remote Hadoop daemons if the optional start and stop scripts are to be used.
1
2
3
4
5
6
mijazz@lenovo ~ ssh localhost
ssh: connect to host localhost port 22: Connection refused
mijazz@lenovo ~ systemctl status sshd
● sshd.service - OpenSSH Daemon
Loaded: loaded (/usr/lib/systemd/system/sshd.service; disabled; vendor preset: disabled)
Active: inactive (dead)
明显没开, 配置一下sshd和限制root远程登录什么的, 还有只允许公匙登录什么的.
sshd_config
1
2
3
4
PasswordAuthentication no
PermitEmptyPasswords no
PubkeyAuthentication yes
PermitRootLogin no
权限记得设0600, Unix/Linux对这类权限要求很严格.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ssh-keygen -t rsa -b 4096
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
mijazz@lenovo ~ sudo systemctl start sshd
[sudo] password for mijazz:
mijazz@lenovo ~ sudo systemctl enable sshd
Created symlink /etc/systemd/system/multi-user.target.wants/sshd.service → /usr/lib/systemd/system/sshd.service.
mijazz@lenovo ~ ssh localhost
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:OvL0/qmZWaRDL66+wbprrEiK4XhNgo1FAU/jRoWIsc0.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
mijazz@lenovo ~ exit
Connection to localhost closed.
公匙免密登录就配置好了
Data Practicing-EP1
Testing Hadoop
EP0中给出的hadoop-3.1.4.tar.gz
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
mijazz@lenovo ~/devEnvs tar -xf ./hadoop-3.1.4.tar.gz
# 文件结构
mijazz@lenovo ~/devEnvs tree -L 1 ./hadoop-3.1.4
./hadoop-3.1.4
├── LICENSE.txt
├── NOTICE.txt
├── README.txt
├── bin # 可执行
├── etc # 配置
├── include
├── lib
├── libexec
├── sbin # 可执行
└── share
7 directories, 3 files
严格按着官网给出的doc配置
Unpack the downloaded Hadoop distribution. In the distribution, edit the file etc/hadoop/hadoop-env.sh to define some parameters as follows:
也就是让我们在hadoop下的配置路径下, 在加上一次JAVA_HOME的路径.
严格来讲~/.bashrc ~/.zshrc环境下有就行
1
echo 'export JAVA_HOME=/home/mijazz/devEnvs/OpenJDK8' >> ./hadoop-3.1.4/etc/hadoop/hadoop-env.sh
然后启动一次hadoop
1
2
3
4
5
6
7
8
9
10
mijazz@lenovo ~/devEnvs/hadoop-3.1.4 ./bin/hadoop
Usage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--config dir Hadoop config directory
--debug turn on shell script debug mode
...............
Configure Hadoop
官方文档推荐在
etc/hadoop/core-site.xml和etc/hadoop/hdfs-site.xml下各添加一个字段.此处不表, 直接贴出上述两个文件.
core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mijazz/devEnvs/hadoop-3.1.4/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.servicerpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.http-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.namenode.https-bind-host</name>
<value>0.0.0.0</value>
</property>
</configuration>
比官网多出来的这几个字段, 方便
interface bind. 也就是都监听.因为之前我尝试在虚拟机
(CentOS8: 192.168.123.5/24, 172.16.0.2/24)和宿主机(Windows10: 192.168.123.2/24, 172.16.0.1/24)和另一台PC(CentOS7: 192.168.123.4/24, 10.100.0.2/16(OpenVPN-NAT))之间尝试做分布式. 这几个选项对我的恶心人的网络拓扑(又是host-only, bridge, openvpn-nat)很有帮助. 官方文档HDFS Support for Multihomed Networks
避坑环境变量
老样子, 追加
~/.zshrc和~/.bashrc
1
2
3
4
5
6
7
8
export HADOOP_HOME="/home/mijazz/devEnvs/hadoop-3.1.4"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
Configure HDFS
引用一下官方文档两张简洁明了的图
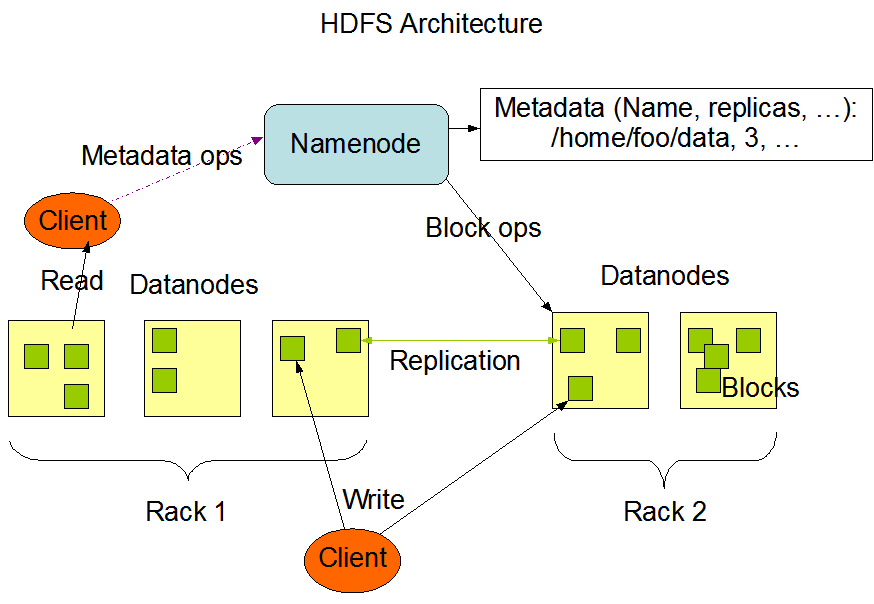
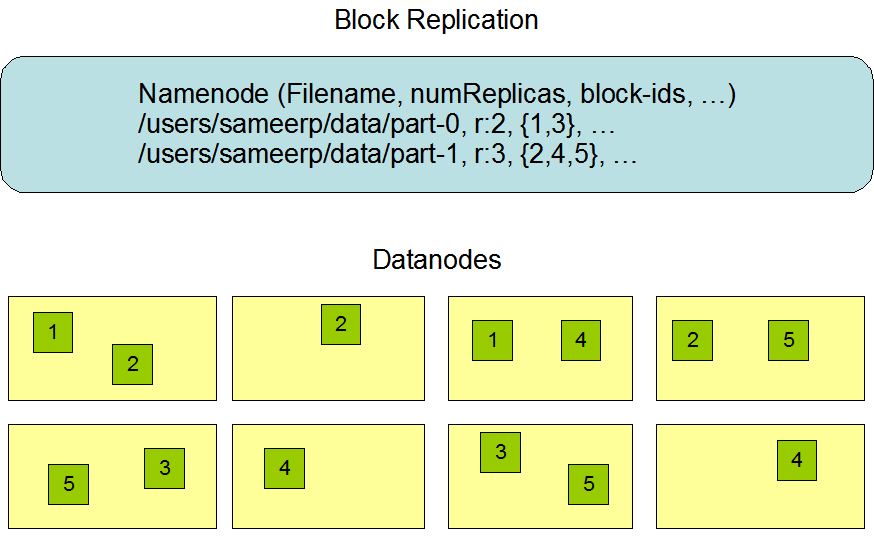
官方文档叙述的架构非常易懂.
这里只提其对用户暴露出的Shell Commands接口, 其命令与Unix/Linux默认文件系统的接口非常类似.
1
mijazz@lenovo ~/devEnvs/hadoop-3.1.4 ./bin/hdfs dfs -help
即可获得其描述.
继续配置HDFS
先对NameNode也就是hdfs的master做一下格式化
1
2
3
4
5
6
7
8
9
mijazz@lenovo ~/devEnvs/hadoop-3.1.4 ./bin/hdfs namenode -format
WARNING: /home/mijazz/devEnvs/hadoop-3.1.4/logs does not exist. Creating.
2020-11-25 23:49:55,071 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = lenovo/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.4
.............
然后同时启动DataNode和NameNode
1
2
3
4
mijazz@lenovo ~/devEnvs/hadoop-3.1.4 ./sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [lenovo]
这里可以看到
NameNode和DataNode的主机名并不一致, 因为之前配置的ssh登录就是在这里起作用的. 因为HDFS主要面向集群, 也就是NameNode-Master和DataNodes-Slaves大多配置在不同的机器上, 其之间的通信都是通过ssh的. 尽管当前部署是本地单机部署, 他还是会用ssh和本地的sshd来进行沟通.
然后访问http://localhost:9870如果看到hadoop就行.
可能会遇到的坑
启动了上述命令, 但是访问localhost:9870没反映
那就尝试做一下问题定位
- 先看看其是不是成功启动了, 用
jps看看就行.
发现没有Java进程在运行.
到%HADOOP_HOME/logs下找日志就行
1
2
3
4
5
6
2020-11-25 23:59:57,076 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: RECEIVED SIGNAL 1: SIGHUP
2020-11-25 23:59:57,076 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: RECEIVED SIGNAL 15: SIGTERM
2020-11-25 23:59:57,088 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DataNode at lenovo/127.0.1.1
************************************************************/
看到了一些奇怪的东西127.0.1.1. 该指向在默认的hosts中存在, 具体原因不表, 具体情况因Linux发行版而异.
看到这里, 很明显是主机名被解析到了一个不能访问到本机的ip上, 导致是DataNode和NameNode之前没心跳.
1
2
3
4
5
mijazz@lenovo ~/devEnvs/hadoop-3.1.4/logs cat /etc/hosts
# Host addresses
127.0.0.1 localhost
127.0.1.1 lenovo # Here
.............
简单修改就行.
1
2
3
4
5
mijazz@lenovo ~ cat /etc/hosts
# Host addresses
127.0.0.1 localhost
127.0.0.1 lenovo # 127.0.0.1
............
还是启动不了, 尝试一下用
hadoop namenode和hadoop datanode放在shell里启动. 如果此时jps能看到活的进程, 并且curl localhost:9870有返回, 后续可以尝试:有条件可以去读一下几个启动脚本的源码, 如果启动脚本拉起不了, 既有可能是目录权限问题或者用户权限问题.
因为官方本就推荐hadoop运行于一个独立的用户/用户组.
1 2 3
stop-all.sh hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode
Configure YARN
YARN = Yet Another Resource Negotiator
什么是YARN -> YARN Architechture
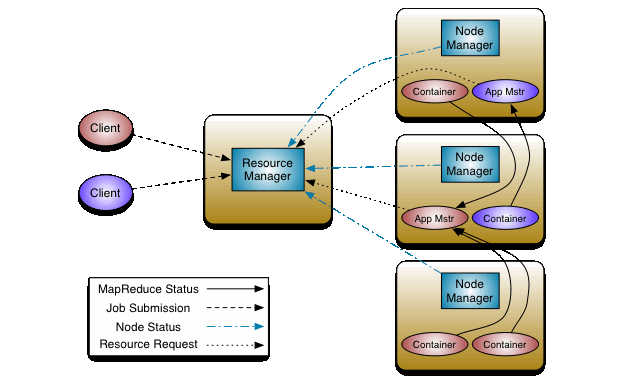
继续贴我自己使用的配置文件
etc/hadoop/mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.webapp.ui2.enable</name>
<value>true</value>
</property>
</configuration>
直接用命令拉起NodeManager和ResourceManager即可.
1
mijazz@lenovo ~/devEnvs/hadoop-3.1.4 start-yarn.sh
可能的坑
用该命令拉起尝试即可
1
2
3
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
yarn-daemon.sh start historyserver
另外定位%HADOOP_HOME/logs下即可.
有个隐藏的坑
随后再更新
Minor Adjustment
如果报Unable to load native-hadoop library for your platform
试着执行
1
mijazz@lenovo ~/devEnvs hadoop checknative
如果下列是一堆no, 不要上百度找答案, 百度上还有说不带lib的.
只需要在etc/hadoop/hadoop-env.sh追加一个JVM参数就行.
1
export HADOOP_OPTS="${HADOOP_OPTS} -Djava.library.path=${HADOOP_HOME}/lib/native"
随后
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
mijazz@lenovo ~/devEnvs/spark-2.4.7 hadoop checknative
2020-11-27 17:49:39,805 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
2020-11-27 17:49:39,809 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
2020-11-27 17:49:39,817 WARN erasurecode.ErasureCodeNative: ISA-L support is not available in your platform... using builtin-java codec where applicable
2020-11-27 17:49:39,864 INFO nativeio.NativeIO: The native code was built without PMDK support.
Native library checking:
hadoop: true /home/mijazz/devEnvs/hadoop-3.1.4/lib/native/libhadoop.so.1.0.0
zlib: true /usr/lib/libz.so.1
zstd : true /usr/lib/libzstd.so.1
snappy: true /usr/lib/libsnappy.so.1
lz4: true revision:10301
bzip2: true /usr/lib/libbz2.so.1
openssl: false EVP_CIPHER_CTX_cleanup
ISA-L: false libhadoop was built without ISA-L support
PMDK: false The native code was built without PMDK support.
再次运行时警告就会消失.
验证
http://your.host.or.ip:9870
http://you.host.or.ip:8088
jps1 2 3 4 5 6 7
mijazz@lenovo ~/devEnvs/hadoop-3.1.4 jps 2160 NameNode 7297 Jps 6084 ApplicationHistoryServer 2551 ResourceManager 2413 NodeManager 2237 DataNode
Data Practicing-EP2
Testing Spark
EP0中的spark
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
mijazz@lenovo ~/devEnvs ll -a
total 161M
drwxr-xr-x 8 mijazz mijazz 4.0K Nov 27 17:27 .
drwx------ 38 mijazz mijazz 4.0K Nov 27 17:27 ..
drwxr-xr-x 8 mijazz mijazz 4.0K Nov 9 20:23 OpenJDK8
drwxr-xr-x 11 mijazz mijazz 4.0K Nov 25 23:49 hadoop-3.1.4
-rw-r--r-- 1 mijazz mijazz 161M Nov 24 16:49 spark-2.4.7-bin-without-hadoop.tgz
mijazz@lenovo ~/devEnvs tar -xf spark-2.4.7-bin-without-hadoop.tgz
mijazz@lenovo ~/devEnvs mv ./spark-2.4.7-bin-without-hadoop ./spark-2.4.7
mijazz@lenovo ~/devEnvs tree -L 1 ./spark-2.4.7
./spark-2.4.7
├── LICENSE
├── NOTICE
├── R
├── README.md
├── RELEASE
├── bin
├── conf
├── data
├── examples
├── jars
├── kubernetes
├── licenses
├── python
├── sbin
└── yarn
11 directories, 4 files
Configure Spark
老样子, 变量~/.zshrc, ~/.bashrc
1
2
3
4
5
# Spark Environment Variable
export SPARK_HOME="/home/mijazz/devEnvs/spark-2.4.7"
export PATH="$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin"
export HADOOP_CONF_DIR="${HADOOP_HOME}/etc/hadoop"
export SPARK_DIST_CLASSPATH="$(hadoop classpath)"
spark下也有conf, 看一眼
1
2
3
4
5
6
7
8
9
10
11
mijazz@lenovo ~/devEnvs/spark-2.4.7 tree ./conf
./conf
├── docker.properties.template
├── fairscheduler.xml.template
├── log4j.properties.template
├── metrics.properties.template
├── slaves.template
├── spark-defaults.conf.template
└── spark-env.sh.template
0 directories, 7 files
这些template里面都写着spark的默认配置.
1
2
3
4
5
6
7
8
9
10
mijazz@lenovo ~/devEnvs/spark-2.4.7 cat ./conf/spark-defaults.conf.template
# ...
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
但是默认的spark是有pre-built with hadoop的. 这次我是采用的自己的hadoop分离开搭建, 以便spark的RDD和hadoop的MapReduce我都能分开用.
所以这次的spark的运行模式是yarn -> YARN on Hadoop, 所以spark.master字段要改yarn
直接上配置
spark-defaults.conf
1
2
3
4
5
6
7
8
spark.master yarn
spark.eventLog.enabled true
# 如果你在定义hadoop的hdfs时采用了自定义端口, 在这里更改
spark.eventLog.dir hdfs://localhost:9000/tmp/spark-logs
spark.history.provider org.apache.spark.deploy.history.FsHistoryProvider
spark.history.fs.logDirectory hdfs://localhost:9000/tmp/spark-logs
spark.history.fs.update.interval 10s
spark.history.ui.port 18080
历史记录应该是可以记录在本地的, 但是为了方便, 此处将其一共上传至hdfs, 方便追溯job history.
1
start-history-server.sh
可能遇到的坑
hdfs里的/tmp权限默认应该是可写的, 但是有可能在拉起记录进程的时候, 他访问文件夹的时候, 空的时候它不去创建.
1
2
3
4
5
6
7
8
9
10
11
12
13
✘ mijazz@lenovo ~/devEnvs/spark-2.4.7 start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /home/mijazz/devEnvs/spark-2.4.7/logs/spark-mijazz-org.apache.spark.deploy.history.HistoryServer-1-lenovo.out
failed to launch: nice -n 0 /home/mijazz/devEnvs/spark-2.4.7/bin/spark-class org.apache.spark.deploy.history.HistoryServer
at org.apache.spark.deploy.history.FsHistoryProvider.<init>(FsHistoryProvider.scala:207)
at org.apache.spark.deploy.history.FsHistoryProvider.<init>(FsHistoryProvider.scala:86)
... 6 more
Caused by: java.io.FileNotFoundException: File does not exist: hdfs://localhost:9000/spark-logs
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1586)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1579)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1594)
at org.apache.spark.deploy.history.FsHistoryProvider.org$apache$spark$deploy$history$FsHistoryProvider$$startPolling(FsHistoryProvider.scala:257)
... 9 more
用hdfs dfs -mkdir /tmp/spark-logs再hdfs dfs -ls /tmp确认一下7xx权限即可.
Running Spark
cluster client模式, cluster模式.
先理解一下spark的运行结构
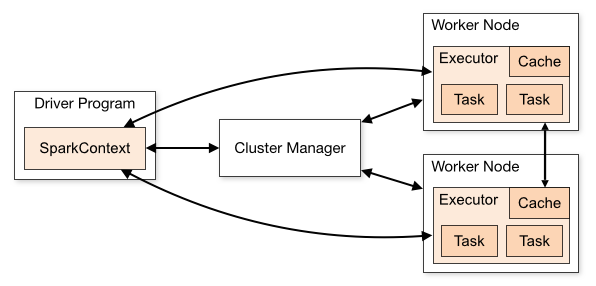
测试一下http://your.ip.or.host:18080
查看history server能不能拉起. 因为其也是作为yarn运行hadoop上的, 所以此处的ip应该是master的.
按照包里给出的example jar, 用spark-submit来提交jar包运行.
1
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.7.jar 10
至于cluster模式和client模式, 主要看spark driver运行在哪一侧. 如果是cluster模式, 在该次作业中, spark会把driver也交给yarn master来运行.
1
2
2020-11-29 15:56:51,224 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 0.920297 s
Pi is roughly 3.1402631402631402
如果成功, 可以看到有该行输出. 记得| grep "Pi is roughly".
同时也将会在Spark History Server即18080端口, 和Yarn Cluster即8088端口看见yarn spark的运行记录以及event logs.
参考运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
mijazz@lenovo ~/devEnvs/spark-2.4.7 spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.7.jar 10
2020-11-29 15:56:38,173 WARN util.Utils: Your hostname, lenovo resolves to a loopback address: 127.0.0.1; using 192.168.123.2 instead (on interface enp4s0)
2020-11-29 15:56:38,173 WARN util.Utils: Set SPARK_LOCAL_IP if you need to bind to another address
2020-11-29 15:56:38,404 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2020-11-29 15:56:38,541 INFO spark.SparkContext: Running Spark version 2.4.7
2020-11-29 15:56:38,556 INFO spark.SparkContext: Submitted application: Spark Pi
2020-11-29 15:56:38,593 INFO spark.SecurityManager: Changing view acls to: mijazz
2020-11-29 15:56:38,593 INFO spark.SecurityManager: Changing modify acls to: mijazz
2020-11-29 15:56:38,593 INFO spark.SecurityManager: Changing view acls groups to:
2020-11-29 15:56:38,593 INFO spark.SecurityManager: Changing modify acls groups to:
2020-11-29 15:56:38,594 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(mijazz); groups with view permissions: Set(); users with modify permissions: Set(mijazz); groups with modify permissions: Set()
2020-11-29 15:56:38,771 INFO util.Utils: Successfully started service 'sparkDriver' on port 39113.
2020-11-29 15:56:38,790 INFO spark.SparkEnv: Registering MapOutputTracker
2020-11-29 15:56:38,802 INFO spark.SparkEnv: Registering BlockManagerMaster
2020-11-29 15:56:38,804 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2020-11-29 15:56:38,805 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
2020-11-29 15:56:38,811 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-01fd513c-7e08-401b-b6ea-46a0a268accf
2020-11-29 15:56:38,823 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB
2020-11-29 15:56:38,857 INFO spark.SparkEnv: Registering OutputCommitCoordinator
2020-11-29 15:56:38,915 INFO util.log: Logging initialized @1320ms
2020-11-29 15:56:38,955 INFO server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: 2019-08-14T05:28:18+08:00, git hash: 84700530e645e812b336747464d6fbbf370c9a20
2020-11-29 15:56:38,972 INFO server.Server: Started @1378ms
2020-11-29 15:56:38,989 INFO server.AbstractConnector: Started ServerConnector@33aa93c{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2020-11-29 15:56:38,989 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
2020-11-29 15:56:39,006 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6bd51ed8{/jobs,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,007 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3b65e559{/jobs/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,007 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@bae47a0{/jobs/job,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,009 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1c05a54d{/jobs/job/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,010 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@65ef722a{/stages,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,010 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5fd9b663{/stages/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,011 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@214894fc{/stages/stage,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,012 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1c4ee95c{/stages/stage/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,012 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@79c4715d{/stages/pool,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,013 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5aa360ea{/stages/pool/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,013 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6548bb7d{/storage,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,013 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@e27ba81{/storage/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,014 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@54336c81{/storage/rdd,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,014 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1556f2dd{/storage/rdd/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,015 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@35e52059{/environment,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,015 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@62577d6{/environment/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,016 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@49bd54f7{/executors,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,016 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6b5f8707{/executors/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,017 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@772485dd{/executors/threadDump,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,017 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5a12c728{/executors/threadDump/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,022 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@79ab3a71{/static,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,023 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5a772895{/,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,024 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@39fc6b2c{/api,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,024 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7cc9ce8{/jobs/job/kill,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,025 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2e27d72f{/stages/stage/kill,null,AVAILABLE,@Spark}
2020-11-29 15:56:39,026 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://lenovo.lan:4040
2020-11-29 15:56:39,035 INFO spark.SparkContext: Added JAR file:/home/mijazz/devEnvs/spark-2.4.7/examples/jars/spark-examples_2.11-2.4.7.jar at spark://lenovo.lan:39113/jars/spark-examples_2.11-2.4.7.jar with timestamp 1606636599035
2020-11-29 15:56:39,634 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2020-11-29 15:56:39,880 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers
2020-11-29 15:56:39,933 INFO conf.Configuration: resource-types.xml not found
2020-11-29 15:56:39,933 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-11-29 15:56:39,945 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
2020-11-29 15:56:39,946 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
2020-11-29 15:56:39,946 INFO yarn.Client: Setting up container launch context for our AM
2020-11-29 15:56:39,948 INFO yarn.Client: Setting up the launch environment for our AM container
2020-11-29 15:56:39,951 INFO yarn.Client: Preparing resources for our AM container
2020-11-29 15:56:39,978 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
2020-11-29 15:56:40,534 INFO yarn.Client: Uploading resource file:/tmp/spark-49c12823-b6a4-4c2e-b397-d77a78188b8d/__spark_libs__1519230271046889967.zip -> hdfs://localhost:9000/user/mijazz/.sparkStaging/application_1606634326109_0003/__spark_libs__1519230271046889967.zip
2020-11-29 15:56:41,208 INFO yarn.Client: Uploading resource file:/tmp/spark-49c12823-b6a4-4c2e-b397-d77a78188b8d/__spark_conf__3120810522893336741.zip -> hdfs://localhost:9000/user/mijazz/.sparkStaging/application_1606634326109_0003/__spark_conf__.zip
2020-11-29 15:56:41,266 INFO spark.SecurityManager: Changing view acls to: mijazz
2020-11-29 15:56:41,266 INFO spark.SecurityManager: Changing modify acls to: mijazz
2020-11-29 15:56:41,266 INFO spark.SecurityManager: Changing view acls groups to:
2020-11-29 15:56:41,266 INFO spark.SecurityManager: Changing modify acls groups to:
2020-11-29 15:56:41,266 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(mijazz); groups with view permissions: Set(); users with modify permissions: Set(mijazz); groups with modify permissions: Set()
2020-11-29 15:56:42,004 INFO yarn.Client: Submitting application application_1606634326109_0003 to ResourceManager
2020-11-29 15:56:42,039 INFO impl.YarnClientImpl: Submitted application application_1606634326109_0003
2020-11-29 15:56:42,041 INFO cluster.SchedulerExtensionServices: Starting Yarn extension services with app application_1606634326109_0003 and attemptId None
2020-11-29 15:56:43,046 INFO yarn.Client: Application report for application_1606634326109_0003 (state: ACCEPTED)
2020-11-29 15:56:43,048 INFO yarn.Client:
client token: N/A
diagnostics: AM container is launched, waiting for AM container to Register with RM
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1606636602015
final status: UNDEFINED
tracking URL: http://localhost:8088/proxy/application_1606634326109_0003/
user: mijazz
2020-11-29 15:56:44,050 INFO yarn.Client: Application report for application_1606634326109_0003 (state: ACCEPTED)
2020-11-29 15:56:45,052 INFO yarn.Client: Application report for application_1606634326109_0003 (state: ACCEPTED)
2020-11-29 15:56:45,963 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> localhost, PROXY_URI_BASES -> http://localhost:8088/proxy/application_1606634326109_0003), /proxy/application_1606634326109_0003
2020-11-29 15:56:46,054 INFO yarn.Client: Application report for application_1606634326109_0003 (state: RUNNING)
2020-11-29 15:56:46,054 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.123.2
ApplicationMaster RPC port: -1
queue: default
start time: 1606636602015
final status: UNDEFINED
tracking URL: http://localhost:8088/proxy/application_1606634326109_0003/
user: mijazz
2020-11-29 15:56:46,055 INFO cluster.YarnClientSchedulerBackend: Application application_1606634326109_0003 has started running.
2020-11-29 15:56:46,061 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 37581.
2020-11-29 15:56:46,061 INFO netty.NettyBlockTransferService: Server created on lenovo.lan:37581
2020-11-29 15:56:46,062 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2020-11-29 15:56:46,079 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, lenovo.lan, 37581, None)
2020-11-29 15:56:46,080 INFO storage.BlockManagerMasterEndpoint: Registering block manager lenovo.lan:37581 with 366.3 MB RAM, BlockManagerId(driver, lenovo.lan, 37581, None)
2020-11-29 15:56:46,082 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, lenovo.lan, 37581, None)
2020-11-29 15:56:46,083 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, lenovo.lan, 37581, None)
2020-11-29 15:56:46,143 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
2020-11-29 15:56:46,205 INFO ui.JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /metrics/json.
2020-11-29 15:56:46,210 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@9e02f84{/metrics/json,null,AVAILABLE,@Spark}
2020-11-29 15:56:46,306 INFO scheduler.EventLoggingListener: Logging events to hdfs://localhost:9000/tmp/spark-logs/application_1606634326109_0003
2020-11-29 15:56:49,276 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.123.2:37340) with ID 1
2020-11-29 15:56:49,394 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:35819 with 366.3 MB RAM, BlockManagerId(1, localhost, 35819, None)
2020-11-29 15:56:49,976 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.123.2:37344) with ID 2
2020-11-29 15:56:50,034 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
2020-11-29 15:56:50,165 INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost:40629 with 366.3 MB RAM, BlockManagerId(2, localhost, 40629, None)
2020-11-29 15:56:50,304 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:38
2020-11-29 15:56:50,319 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 10 output partitions
2020-11-29 15:56:50,320 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
2020-11-29 15:56:50,321 INFO scheduler.DAGScheduler: Parents of final stage: List()
2020-11-29 15:56:50,321 INFO scheduler.DAGScheduler: Missing parents: List()
2020-11-29 15:56:50,325 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
2020-11-29 15:56:50,436 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 2.0 KB, free 366.3 MB)
2020-11-29 15:56:50,454 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1381.0 B, free 366.3 MB)
2020-11-29 15:56:50,456 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on lenovo.lan:37581 (size: 1381.0 B, free: 366.3 MB)
2020-11-29 15:56:50,459 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1184
2020-11-29 15:56:50,471 INFO scheduler.DAGScheduler: Submitting 10 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6, 7, 8, 9))
2020-11-29 15:56:50,471 INFO cluster.YarnScheduler: Adding task set 0.0 with 10 tasks
2020-11-29 15:56:50,496 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor 2, partition 0, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:50,500 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor 1, partition 1, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:50,783 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:35819 (size: 1381.0 B, free: 366.3 MB)
2020-11-29 15:56:50,976 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:40629 (size: 1381.0 B, free: 366.3 MB)
2020-11-29 15:56:51,003 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, executor 1, partition 2, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,008 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 509 ms on localhost (executor 1) (1/10)
2020-11-29 15:56:51,039 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, localhost, executor 1, partition 3, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,042 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 40 ms on localhost (executor 1) (2/10)
2020-11-29 15:56:51,075 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, localhost, executor 1, partition 4, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,078 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 39 ms on localhost (executor 1) (3/10)
2020-11-29 15:56:51,110 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, localhost, executor 2, partition 5, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,112 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 627 ms on localhost (executor 2) (4/10)
2020-11-29 15:56:51,122 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, localhost, executor 1, partition 6, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,123 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 47 ms on localhost (executor 1) (5/10)
2020-11-29 15:56:51,166 INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7, localhost, executor 1, partition 7, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,171 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 49 ms on localhost (executor 1) (6/10)
2020-11-29 15:56:51,171 INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8, localhost, executor 2, partition 8, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,172 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 62 ms on localhost (executor 2) (7/10)
2020-11-29 15:56:51,187 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9, localhost, executor 1, partition 9, PROCESS_LOCAL, 7877 bytes)
2020-11-29 15:56:51,188 INFO scheduler.TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 22 ms on localhost (executor 1) (8/10)
2020-11-29 15:56:51,213 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 42 ms on localhost (executor 2) (9/10)
2020-11-29 15:56:51,219 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 33 ms on localhost (executor 1) (10/10)
2020-11-29 15:56:51,220 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
2020-11-29 15:56:51,221 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 0.868 s
2020-11-29 15:56:51,224 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 0.920297 s
Pi is roughly 3.1402631402631402
2020-11-29 15:56:51,235 INFO server.AbstractConnector: Stopped Spark@33aa93c{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2020-11-29 15:56:51,237 INFO ui.SparkUI: Stopped Spark web UI at http://lenovo.lan:4040
2020-11-29 15:56:51,240 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
2020-11-29 15:56:51,263 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
2020-11-29 15:56:51,264 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
2020-11-29 15:56:51,268 INFO cluster.SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,
services=List(),
started=false)
2020-11-29 15:56:51,268 INFO cluster.YarnClientSchedulerBackend: Stopped
2020-11-29 15:56:51,364 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2020-11-29 15:56:51,371 INFO memory.MemoryStore: MemoryStore cleared
2020-11-29 15:56:51,371 INFO storage.BlockManager: BlockManager stopped
2020-11-29 15:56:51,374 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2020-11-29 15:56:51,376 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2020-11-29 15:56:51,398 INFO spark.SparkContext: Successfully stopped SparkContext
2020-11-29 15:56:51,400 INFO util.ShutdownHookManager: Shutdown hook called
2020-11-29 15:56:51,401 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-5c235e44-e3d3-4d12-923c-a635b9143c39
2020-11-29 15:56:51,403 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-49c12823-b6a4-4c2e-b397-d77a78188b8d
Data Practicing-EP3
Introduce Spark
这里贴出几个官方文档
这里只记录一下SparkRDD, RDD -> Resilient Distributed Datasets.
它是一种可扩展的弹性分布式数据集, 他是只读的, 分区的, 并且保持不变的数据集合, 直接与在内存层面的一个分布式实现.
- 可分区/片(
默认好象是Hash分区?) - 可自定义分片计算函数
- 互相依赖(下个分区由之前的分区通过转换生成)
- 可控制分片数量
- 可以使用列表方式进行块储存
它支持两种类型的操作
- Transformations
map()flatMap()filter()union()intersection()- ……
- Actions
reduce()collect()count()- ……
RDD Operations Examples
以下Code Block均为在
Spark-shell下执行的结果
Spark-> 2.4.7YarnonHadoop 3.1.4
Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_275)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
scala> val data = Array(2, 3, 5, 7, 11)
data: Array[Int] = Array(2, 3, 5, 7, 11)
scala> val rdd1 = sc.parallelize(data)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26
scala> val rdd2 = rdd1.map(element => (element*2, element*element)).collect()
rdd2: Array[(Int, Int)] = Array((4,4), (6,9), (10,25), (14,49), (22,121))
scala> val rdd3 = rdd1.union(rdd1)
rdd3: org.apache.spark.rdd.RDD[Int] = UnionRDD[3] at union at <console>:25
scala> rdd3.collect()
res4: Array[Int] = Array(2, 3, 5, 7, 11, 2, 3, 5, 7, 11)
scala> rdd3.sortBy(x => x%8, ascending=false).collect()
res5: Array[Int] = Array(7, 7, 5, 5, 11, 3, 3, 11, 2, 2)
scala> rdd3.count()
res6: Long = 10
scala> rdd3.take(3)
res7: Array[Int] = Array(2, 3, 5)
scala> rdd3.distinct().collect()
res8: Array[Int] = Array(5, 2, 11, 3, 7)
........
加上之前我们在hadoop里运行的HDFS, Spark可以很方便的通过hdfs://ip.or.host:port/path/to/file来访问hdfs的文件.
也可以使用spark sql在处理数据.
Prepare to Code
网上太多教材关于Spark + Scala + IntelliJ IDEA + sbt四大件的了
贴几个教程链接
包管理对于我来说, 还是更熟悉Java的那一套, 毕竟Spring用多了. 不是Maven就是Gradle.
镜像设置过程不表, 见Aliyun Maven Mirror
Manjaro Linux 20
IntelliJ IDEA Ultimate 2020.2.3
Maven(bundled with idea, 3.6.3)
Install Scala Plugin in IDEA(!important)
常规IDEA建立Maven的Project, 依赖如下
pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.7</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.7</version>
</dependency>
</dependencies>
如果spark版本不同, 去mvnrepository搜索对应的依赖, 粘贴进依赖区即可.
Sync一下, Maven即可解决依赖问题. 而后在工程下右键, Add Framework Support, 加入该工程对Scala的支持.(该步骤需要有Scala Plugin)
常规建包建类即可, 选Scala Class -> Object
我的步骤
$Project Root/src/main/java新建
package->edu.zstu.mijazz.sparklearn包下建类
Scala Object -> HelloWorld1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
package edu.zstu.mijazz.sparklearn1 import org.apache.spark.sql.SparkSession import scala.math.random object HelloWorld { def main(args: Array[String]): Unit = { val spark = SparkSession.builder.appName("Spark Pi").master("local").getOrCreate() val count = spark.sparkContext.parallelize(1 until 50000000, 3).map {_ => val x = random * 2 - 1 val y = random * 2 - 1 if (x*x + y*y <= 1) 1 else 0 }.reduce(_ + _) println(s"Pi is roughly ${4.0 * count / (50000000 - 1)}") spark.stop() spark.close() } }
直接建object, 执行时对象初始化触发对象
main(), 至于Scala的语法和资料, 见Scala Docs如果输出没问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 20/11/29 22:21:24 INFO SparkContext: Running Spark version 2.4.7 20/11/29 22:21:24 INFO SparkContext: Submitted application: Spark Pi 20/11/29 22:21:24 INFO SecurityManager: Changing view acls to: mijazz 20/11/29 22:21:24 INFO SecurityManager: Changing modify acls to: mijazz 20/11/29 22:21:24 INFO SecurityManager: Changing view acls groups to: 20/11/29 22:21:24 INFO SecurityManager: Changing modify acls groups to: 20/11/29 22:21:24 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(mijazz); groups with view permissions: Set(); users with modify permissions: Set(mijazz); groups with modify permissions: Set() 20/11/29 22:21:24 INFO Utils: Successfully started service 'sparkDriver' on port 46007. 20/11/29 22:21:24 INFO SparkEnv: Registering MapOutputTracker 20/11/29 22:21:24 INFO SparkEnv: Registering BlockManagerMaster 20/11/29 22:21:25 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information 20/11/29 22:21:25 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up 20/11/29 22:21:25 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-be049433-3f00-4037-a865-67cd6f445fba 20/11/29 22:21:25 INFO MemoryStore: MemoryStore started with capacity 1941.6 MB 20/11/29 22:21:25 INFO SparkEnv: Registering OutputCommitCoordinator 20/11/29 22:21:25 INFO Utils: Successfully started service 'SparkUI' on port 4040. 20/11/29 22:21:25 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://lenovo.lan:4040 20/11/29 22:21:25 INFO Executor: Starting executor ID driver on host localhost 20/11/29 22:21:25 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 44811. 20/11/29 22:21:25 INFO NettyBlockTransferService: Server created on lenovo.lan:44811 20/11/29 22:21:25 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy 20/11/29 22:21:25 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, lenovo.lan, 44811, None) 20/11/29 22:21:25 INFO BlockManagerMasterEndpoint: Registering block manager lenovo.lan:44811 with 1941.6 MB RAM, BlockManagerId(driver, lenovo.lan, 44811, None) 20/11/29 22:21:25 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, lenovo.lan, 44811, None) 20/11/29 22:21:25 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, lenovo.lan, 44811, None) 20/11/29 22:21:25 INFO SparkContext: Starting job: reduce at HelloWorld.scala:15 20/11/29 22:21:26 INFO DAGScheduler: Got job 0 (reduce at HelloWorld.scala:15) with 3 output partitions 20/11/29 22:21:26 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at HelloWorld.scala:15) 20/11/29 22:21:26 INFO DAGScheduler: Parents of final stage: List() 20/11/29 22:21:26 INFO DAGScheduler: Missing parents: List() 20/11/29 22:21:26 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at HelloWorld.scala:11), which has no missing parents 20/11/29 22:21:26 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 2.0 KB, free 1941.6 MB) 20/11/29 22:21:26 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1401.0 B, free 1941.6 MB) 20/11/29 22:21:26 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on lenovo.lan:44811 (size: 1401.0 B, free: 1941.6 MB) 20/11/29 22:21:26 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1184 20/11/29 22:21:26 INFO DAGScheduler: Submitting 3 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at HelloWorld.scala:11) (first 15 tasks are for partitions Vector(0, 1, 2)) 20/11/29 22:21:26 INFO TaskSchedulerImpl: Adding task set 0.0 with 3 tasks 20/11/29 22:21:26 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7866 bytes) 20/11/29 22:21:26 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 20/11/29 22:21:27 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 867 bytes result sent to driver 20/11/29 22:21:27 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7866 bytes) 20/11/29 22:21:27 INFO Executor: Running task 1.0 in stage 0.0 (TID 1) 20/11/29 22:21:27 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1038 ms on localhost (executor driver) (1/3) 20/11/29 22:21:28 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 867 bytes result sent to driver 20/11/29 22:21:28 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, executor driver, partition 2, PROCESS_LOCAL, 7866 bytes) 20/11/29 22:21:28 INFO Executor: Running task 2.0 in stage 0.0 (TID 2) 20/11/29 22:21:28 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 998 ms on localhost (executor driver) (2/3) 20/11/29 22:21:29 INFO Executor: Finished task 2.0 in stage 0.0 (TID 2). 867 bytes result sent to driver 20/11/29 22:21:29 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 991 ms on localhost (executor driver) (3/3) 20/11/29 22:21:29 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 20/11/29 22:21:29 INFO DAGScheduler: ResultStage 0 (reduce at HelloWorld.scala:15) finished in 3.169 s 20/11/29 22:21:29 INFO DAGScheduler: Job 0 finished: reduce at HelloWorld.scala:15, took 3.204133 s 20/11/29 22:21:29 INFO SparkUI: Stopped Spark web UI at http://lenovo.lan:4040 Pi is roughly 3.141491662829833 20/11/29 22:21:29 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 20/11/29 22:21:29 INFO MemoryStore: MemoryStore cleared 20/11/29 22:21:29 INFO BlockManager: BlockManager stopped 20/11/29 22:21:29 INFO BlockManagerMaster: BlockManagerMaster stopped 20/11/29 22:21:29 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 20/11/29 22:21:29 INFO SparkContext: Successfully stopped SparkContext 20/11/29 22:21:29 INFO SparkContext: SparkContext already stopped. 20/11/29 22:21:29 INFO ShutdownHookManager: Shutdown hook called 20/11/29 22:21:29 INFO ShutdownHookManager: Deleting directory /tmp/spark-701b3922-5c91-4ada-80de-0319be2db7e3
能够跑出结果, 说明在IDEA中直接使用scala与spark交互已经没问题了. 现在开始找数据集试试DataFrame
Data Practicing-EP4
Find Data
Chicago Crime Data is from
CHICAGO DATA PORTAL
这次使用的是Chicago的Crime Data. 从2001年至最近的.
1
2
3
4
5
6
7
8
mijazz@lenovo ~/devEnvs wc -l chicagoCrimeData.csv
7212274 chicagoCrimeData.csv
mijazz@lenovo ~/devEnvs head -n 2 ./chicagoCrimeData.csv
ID,Case Number,Date,Block,IUCR,Primary Type,Description,Location Description,Arrest,Domestic,Beat,District,Ward,Community Area,FBI Code,X Coordinate,Y Coordinate,Year,Updated On,Latitude,Longitude,Location
11034701,JA366925,01/01/2001 11:00:00 AM,016XX E 86TH PL,1153,DECEPTIVE PRACTICE,FINANCIAL IDENTITY THEFT OVER $ 300,RESIDENCE,false,false,0412,004,8,45,11,,,2001,08/05/2017 03:50:08 PM,,,
mijazz@lenovo ~/devEnvs tail -n 2 ./chicagoCrimeData.csv
11707239,JC287563,11/30/2017 09:00:00 AM,022XX S KOSTNER AVE,1153,DECEPTIVE PRACTICE,FINANCIAL IDENTITY THEFT OVER $ 300,RESIDENCE,false,false,1013,010,22,29,11,,,2017,06/02/2019 04:09:42 PM,,,
24559,JC278908,05/26/2019 02:11:00 AM,013XX W HASTINGS ST,0110,HOMICIDE,FIRST DEGREE MURDER,STREET,false,false,1233,012,25,28,01A,1167746,1893853,2019,06/20/2020 03:48:45 PM,41.864278357,-87.659682244,"(41.864278357, -87.659682244)"
共7,212,274行数据, 每行数据代表一次记录在案的犯罪信息.
部分列描述如下
- ID - Unique Row ID
- Case Number - Unique Chicago Police Department Records Division Number, Unique
- Date
- Block - Address
- IUCR - Illinois Uniform Crime Reporting CodeCode Referrence
- Primary Type - IUCR Code/Crime Description
- Description - Crime Description
- Location Description
- Arrest - Arrest made or not
- Community Area - Community Area Code Code Referrence
- Location - (Latitude, Longitude)
Move to HDFS
前面说过
hdfs的提供的交互shell很像Unix/Linux的文件系统交互.文档如下: File System Shell 或者
hdfs dfs -help
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
mijazz@lenovo ~/devEnvs ll -a
total 1.8G
drwxr-xr-x 10 mijazz mijazz 4.0K Nov 29 22:45 .
drwx------ 42 mijazz mijazz 4.0K Nov 30 15:42 ..
drwxr-xr-x 8 mijazz mijazz 4.0K Nov 9 20:23 OpenJDK8
-rwxrwxrwx 1 mijazz mijazz 1.6G Oct 19 18:05 chicagoCrimeData.csv
drwxr-xr-x 11 mijazz mijazz 4.0K Nov 25 23:49 hadoop-3.1.4
drwxr-xr-x 14 mijazz mijazz 4.0K Nov 29 15:25 spark-2.4.7
-rw-r--r-- 1 mijazz mijazz 161M Nov 24 16:49 spark-2.4.7-bin-without-hadoop.tgz
mijazz@lenovo ~/devEnvs hdfs dfs -mkdir /user/mijazz/chicagoData
mijazz@lenovo ~/devEnvs hdfs dfs -put ./chicagoCrimeData.csv /user/mijazz/chicagoData/originCrimeData.csv
mijazz@lenovo ~/devEnvs hdfs dfs -ls /user/mijazz/chicagoData
Found 1 items
-rw-r--r-- 1 mijazz supergroup 1701238602 2020-11-30 15:43 /user/mijazz/chicagoData/originCrimeData.csv
dfs -put把文件上传上hdfs, 如果需要多用户读写, 检查一下权限即可.dfs -chmod给个666之后,
上传之后, 在spark中就可以通过hdfs://your.ip.or.host:port/path/to/file来访问了.
在我这里就是hdfs://localhost:9000/user/mijazz/chicagoData/originCrimeData.csv
Pre-Processing
在EP3中配置好的IntelliJ IDEA的project, 新建一个Scala Object即可.
前面几行代码都是必备的了
- 用SparkSession拉起一个Spark会话
- Context负责数据
Take a Glance at the Data
Object + main()方法或者Object + extends App 当脚本用
DataPreProcess.scala - 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package edu.zstu.mijazz.sparklearn1
import org.apache.spark.sql.SparkSession
object DataPreProcess {
val HDFS_PATH = "hdfs://localhost:9000/user/mijazz/"
val DATA_PATH = HDFS_PATH + "chicagoData/"
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder.appName("Data Pre-Processing").master("local").getOrCreate()
val sContext = spark.sparkContext
val data = sContext.textFile(DATA_PATH + "originCrimeData.csv")
data.take(3).foreach(println)
}
}
Full Output
后面的输出block, 我会把spark的输出手工砍掉.
当然你也可以在spark中配置比info级别高一些的log level, 但是留着便于我知道内存使用量.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
20/11/30 16:00:51 WARN Utils: Your hostname, lenovo resolves to a loopback address: 127.0.0.1; using 192.168.123.2 instead (on interface enp4s0)
20/11/30 16:00:51 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
20/11/30 16:00:51 INFO SparkContext: Running Spark version 2.4.7
20/11/30 16:00:51 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/11/30 16:00:51 INFO SparkContext: Submitted application: Data Pre-Processing
20/11/30 16:00:51 INFO SecurityManager: Changing view acls to: mijazz
20/11/30 16:00:51 INFO SecurityManager: Changing modify acls to: mijazz
20/11/30 16:00:51 INFO SecurityManager: Changing view acls groups to:
20/11/30 16:00:51 INFO SecurityManager: Changing modify acls groups to:
20/11/30 16:00:51 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(mijazz); groups with view permissions: Set(); users with modify permissions: Set(mijazz); groups with modify permissions: Set()
20/11/30 16:00:52 INFO Utils: Successfully started service 'sparkDriver' on port 35377.
20/11/30 16:00:52 INFO SparkEnv: Registering MapOutputTracker
20/11/30 16:00:52 INFO SparkEnv: Registering BlockManagerMaster
20/11/30 16:00:52 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
20/11/30 16:00:52 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
20/11/30 16:00:52 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-283f5487-ed7e-41b8-92ae-20d56fb33ba5
20/11/30 16:00:52 INFO MemoryStore: MemoryStore started with capacity 1941.6 MB
20/11/30 16:00:52 INFO SparkEnv: Registering OutputCommitCoordinator
20/11/30 16:00:52 INFO Utils: Successfully started service 'SparkUI' on port 4040.
20/11/30 16:00:52 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://lenovo.lan:4040
20/11/30 16:00:52 INFO Executor: Starting executor ID driver on host localhost
20/11/30 16:00:52 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 37555.
20/11/30 16:00:52 INFO NettyBlockTransferService: Server created on lenovo.lan:37555
20/11/30 16:00:52 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
20/11/30 16:00:52 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, lenovo.lan, 37555, None)
20/11/30 16:00:52 INFO BlockManagerMasterEndpoint: Registering block manager lenovo.lan:37555 with 1941.6 MB RAM, BlockManagerId(driver, lenovo.lan, 37555, None)
20/11/30 16:00:52 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, lenovo.lan, 37555, None)
20/11/30 16:00:52 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, lenovo.lan, 37555, None)
20/11/30 16:00:53 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 214.6 KB, free 1941.4 MB)
20/11/30 16:00:53 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 20.4 KB, free 1941.4 MB)
20/11/30 16:00:53 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on lenovo.lan:37555 (size: 20.4 KB, free: 1941.6 MB)
20/11/30 16:00:53 INFO SparkContext: Created broadcast 0 from textFile at DataPreProcess.scala:12
20/11/30 16:00:53 INFO FileInputFormat: Total input paths to process : 1
20/11/30 16:00:53 INFO SparkContext: Starting job: take at DataPreProcess.scala:13
20/11/30 16:00:53 INFO DAGScheduler: Got job 0 (take at DataPreProcess.scala:13) with 1 output partitions
20/11/30 16:00:53 INFO DAGScheduler: Final stage: ResultStage 0 (take at DataPreProcess.scala:13)
20/11/30 16:00:53 INFO DAGScheduler: Parents of final stage: List()
20/11/30 16:00:53 INFO DAGScheduler: Missing parents: List()
20/11/30 16:00:53 INFO DAGScheduler: Submitting ResultStage 0 (hdfs://localhost:9000/user/mijazz/chicagoData/originCrimeData.csv MapPartitionsRDD[1] at textFile at DataPreProcess.scala:12), which has no missing parents
20/11/30 16:00:53 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 3.6 KB, free 1941.4 MB)
20/11/30 16:00:53 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.2 KB, free 1941.4 MB)
20/11/30 16:00:53 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on lenovo.lan:37555 (size: 2.2 KB, free: 1941.6 MB)
20/11/30 16:00:53 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1184
20/11/30 16:00:53 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (hdfs://localhost:9000/user/mijazz/chicagoData/originCrimeData.csv MapPartitionsRDD[1] at textFile at DataPreProcess.scala:12) (first 15 tasks are for partitions Vector(0))
20/11/30 16:00:53 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
20/11/30 16:00:54 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7925 bytes)
20/11/30 16:00:54 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
20/11/30 16:00:54 INFO HadoopRDD: Input split: hdfs://localhost:9000/user/mijazz/chicagoData/originCrimeData.csv:0+134217728
20/11/30 16:00:54 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1371 bytes result sent to driver
20/11/30 16:00:54 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 133 ms on localhost (executor driver) (1/1)
20/11/30 16:00:54 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
20/11/30 16:00:54 INFO DAGScheduler: ResultStage 0 (take at DataPreProcess.scala:13) finished in 0.183 s
20/11/30 16:00:54 INFO DAGScheduler: Job 0 finished: take at DataPreProcess.scala:13, took 0.217644 s
20/11/30 16:00:54 INFO SparkContext: Invoking stop() from shutdown hook
ID,Case Number,Date,Block,IUCR,Primary Type,Description,Location Description,Arrest,Domestic,Beat,District,Ward,Community Area,FBI Code,X Coordinate,Y Coordinate,Year,Updated On,Latitude,Longitude,Location
11034701,JA366925,01/01/2001 11:00:00 AM,016XX E 86TH PL,1153,DECEPTIVE PRACTICE,FINANCIAL IDENTITY THEFT OVER $ 300,RESIDENCE,false,false,0412,004,8,45,11,,,2001,08/05/2017 03:50:08 PM,,,
11227287,JB147188,10/08/2017 03:00:00 AM,092XX S RACINE AVE,0281,CRIM SEXUAL ASSAULT,NON-AGGRAVATED,RESIDENCE,false,false,2222,022,21,73,02,,,2017,02/11/2018 03:57:41 PM,,,
20/11/30 16:00:54 INFO SparkUI: Stopped Spark web UI at http://lenovo.lan:4040
20/11/30 16:00:54 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
20/11/30 16:00:54 INFO MemoryStore: MemoryStore cleared
20/11/30 16:00:54 INFO BlockManager: BlockManager stopped
20/11/30 16:00:54 INFO BlockManagerMaster: BlockManagerMaster stopped
20/11/30 16:00:54 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
20/11/30 16:00:54 INFO SparkContext: Successfully stopped SparkContext
20/11/30 16:00:54 INFO ShutdownHookManager: Shutdown hook called
20/11/30 16:00:54 INFO ShutdownHookManager: Deleting directory /tmp/spark-c6ba3bd3-3fc3-46b8-9e7e-3413981456ff
Process finished with exit code 0
Useful Output
1
2
3
ID,Case Number,Date,Block,IUCR,Primary Type,Description,Location Description,Arrest,Domestic,Beat,District,Ward,Community Area,FBI Code,X Coordinate,Y Coordinate,Year,Updated On,Latitude,Longitude,Location
11034701,JA366925,01/01/2001 11:00:00 AM,016XX E 86TH PL,1153,DECEPTIVE PRACTICE,FINANCIAL IDENTITY THEFT OVER $ 300,RESIDENCE,false,false,0412,004,8,45,11,,,2001,08/05/2017 03:50:08 PM,,,
11227287,JB147188,10/08/2017 03:00:00 AM,092XX S RACINE AVE,0281,CRIM SEXUAL ASSAULT,NON-AGGRAVATED,RESIDENCE,false,false,2222,022,21,73,02,,,2017,02/11/2018 03:57:41 PM,,,
有不少空值.
DataPreProcess.scala - 2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
package edu.zstu.mijazz.sparklearn1
import org.apache.spark.sql.SparkSession
object DataPreProcess extends App {
val HDFS_PATH = "hdfs://localhost:9000/user/mijazz/"
val DATA_PATH = HDFS_PATH + "chicagoData/"
val spark = SparkSession.builder.appName("Data Pre-Processing").master("local").getOrCreate()
val sContext = spark.sparkContext
val crimeDataFrame = spark.read
.option("header", true)
.option("inferSchema", true)
.csv(DATA_PATH + "originCrimeData.csv")
crimeDataFrame.show(3)
crimeDataFrame.printSchema()
spark.stop()
spark.close()
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
+--------+-----------+--------------------+------------------+----+-------------------+--------------------+--------------------+------+--------+----+--------+----+--------------+--------+------------+------------+----+--------------------+--------+---------+--------+
| ID|Case Number| Date| Block|IUCR| Primary Type| Description|Location Description|Arrest|Domestic|Beat|District|Ward|Community Area|FBI Code|X Coordinate|Y Coordinate|Year| Updated On|Latitude|Longitude|Location|
+--------+-----------+--------------------+------------------+----+-------------------+--------------------+--------------------+------+--------+----+--------+----+--------------+--------+------------+------------+----+--------------------+--------+---------+--------+
|11034701| JA366925|01/01/2001 11:00:...| 016XX E 86TH PL|1153| DECEPTIVE PRACTICE|FINANCIAL IDENTIT...| RESIDENCE| false| false| 412| 4| 8| 45| 11| null| null|2001|08/05/2017 03:50:...| null| null| null|
|11227287| JB147188|10/08/2017 03:00:...|092XX S RACINE AVE|0281|CRIM SEXUAL ASSAULT| NON-AGGRAVATED| RESIDENCE| false| false|2222| 22| 21| 73| 02| null| null|2017|02/11/2018 03:57:...| null| null| null|
|11227583| JB147595|03/28/2017 02:00:...| 026XX W 79TH ST|0620| BURGLARY| UNLAWFUL ENTRY| OTHER| false| false| 835| 8| 18| 70| 05| null| null|2017|02/11/2018 03:57:...| null| null| null|
+--------+-----------+--------------------+------------------+----+-------------------+--------------------+--------------------+------+--------+----+--------+----+--------------+--------+------------+------------+----+--------------------+--------+---------+--------+
only showing top 3 rows
root
|-- ID: integer (nullable = true)
|-- Case Number: string (nullable = true)
|-- Date: string (nullable = true)
|-- Block: string (nullable = true)
|-- IUCR: string (nullable = true)
|-- Primary Type: string (nullable = true)
|-- Description: string (nullable = true)
|-- Location Description: string (nullable = true)
|-- Arrest: boolean (nullable = true)
|-- Domestic: boolean (nullable = true)
|-- Beat: integer (nullable = true)
|-- District: integer (nullable = true)
|-- Ward: integer (nullable = true)
|-- Community Area: integer (nullable = true)
|-- FBI Code: string (nullable = true)
|-- X Coordinate: integer (nullable = true)
|-- Y Coordinate: integer (nullable = true)
|-- Year: integer (nullable = true)
|-- Updated On: string (nullable = true)
|-- Latitude: double (nullable = true)
|-- Longitude: double (nullable = true)
|-- Location: string (nullable = true)
Start with Data
为了方便阅读, 多加了一个Java Class - StaticTool.java, 专门用来存静态数据.
1
2
3
4
5
6
7
8
package edu.zstu.mijazz.sparklearn1;
public class StaticTool {
public static final String HDFS_PATH = "hdfs://localhost:9000/user/mijazz/";
public static final String DATA_PATH = HDFS_PATH + "chicagoData/";
public static final String ORIGIN_DATA = DATA_PATH + "originCrimeData.csv";
public static final String DATE_DATA = DATA_PATH + "dateDF.csv";
}
Date Column
万事就先从时间开始吧, 对Date字段先做个分析
1
2
val dateNullRowCount = crimeDataFrame.filter("Date is null").count()
println(dateNullRowCount)
1
0
看到日期值并没有空列, 很好, 不用na.fill了.
foucsDate.scala - 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package edu.zstu.mijazz.sparklearn1
import org.apache.spark.sql.SparkSession
object focusDate extends App {
val spark = SparkSession.builder.appName("Data Pre-Processing").master("local").getOrCreate()
val sContext = spark.sparkContext
val crimeDataFrame = spark.read
.option("header", true)
.option("inferSchema", true)
.csv(StaticTool.DATA_PATH + "originCrimeData.csv")
var dateNeedColumn = crimeDataFrame.select("Date", "Primary Type", "Year")
dateNeedColumn.show(3)
dateNeedColumn.printSchema()
}
1
2
3
4
5
6
7
8
9
10
11
12
13
+--------------------+-------------------+----+
| Date| Primary Type|Year|
+--------------------+-------------------+----+
|01/01/2001 11:00:...| DECEPTIVE PRACTICE|2001|
|10/08/2017 03:00:...|CRIM SEXUAL ASSAULT|2017|
|03/28/2017 02:00:...| BURGLARY|2017|
+--------------------+-------------------+----+
only showing top 3 rows
root
|-- Date: string (nullable = true)
|-- Primary Type: string (nullable = true)
|-- Year: integer (nullable = true)
看到Date字段居然是String类型. 做个cast
foucsDate.scala - 2
1
2
3
4
5
6
7
8
dateNeedColumn = dateNeedColumn
.withColumn("TimeStamp", unix_timestamp(
col("Date"), "MM/dd/yyyy HH:mm:ss").cast("timestamp"))
.drop("Date")
.withColumnRenamed("Primary Type", "Crime")
dateNeedColumn.show(3)
dateNeedColumn.printSchema()
1
2
3
4
5
6
7
8
9
10
11
12
13
+-------------------+----+-------------------+
| Crime|Year| TimeStamp|
+-------------------+----+-------------------+
| DECEPTIVE PRACTICE|2001|2001-01-01 11:00:00|
|CRIM SEXUAL ASSAULT|2017|2017-10-08 03:00:00|
| BURGLARY|2017|2017-03-28 02:00:00|
+-------------------+----+-------------------+
only showing top 3 rows
root
|-- Crime: string (nullable = true)
|-- Year: integer (nullable = true)
|-- TimeStamp: timestamp (nullable = true)
把时间都砍出来, 日期或者月份拿来做汇总, 时间用来后期画图?
focusDate.scala - 3
1
2
3
4
5
6
7
8
9
dateNeedColumn = dateNeedColumn
.withColumn("Year", col("Year"))
.withColumn("Month", col("TimeStamp").substr(0, 7))
.withColumn("Day", col("TimeStamp").substr(0, 10))
.withColumn("Hour", col("TimeStamp").substr(11, 3))
.withColumnRenamed("Location Description", "Location")
dateNeedColumn.show(5)
dateNeedColumn.printSchema()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
+-------------------+----+-----------+-------------------+-------+----------+----+
| Crime|Year| Location| TimeStamp| Month| Day|Hour|
+-------------------+----+-----------+-------------------+-------+----------+----+
| DECEPTIVE PRACTICE|2001| RESIDENCE|2001-01-01 11:00:00|2001-01|2001-01-01| 11|
|CRIM SEXUAL ASSAULT|2017| RESIDENCE|2017-10-08 03:00:00|2017-10|2017-10-08| 03|
| BURGLARY|2017| OTHER|2017-03-28 02:00:00|2017-03|2017-03-28| 02|
| THEFT|2017| RESIDENCE|2017-09-09 08:17:00|2017-09|2017-09-09| 08|
|CRIM SEXUAL ASSAULT|2017|HOTEL/MOTEL|2017-08-26 10:00:00|2017-08|2017-08-26| 10|
+-------------------+----+-----------+-------------------+-------+----------+----+
only showing top 5 rows
root
|-- Crime: string (nullable = true)
|-- Year: integer (nullable = true)
|-- Location: string (nullable = true)
|-- TimeStamp: timestamp (nullable = true)
|-- Month: string (nullable = true)
|-- Day: string (nullable = true)
|-- Hour: string (nullable = true)
Write Data to CSV
focusDate.scala - 4
1
dateNeedColumn.write.option("header", true).csv(StaticTool.DATA_PATH + "dateDF.csv")
Crime Column
提取完日期, 然后看看Crime列到底有多少种犯罪
focusCrime.scala - 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package edu.zstu.mijazz.sparklearn1
import org.apache.spark.sql.SparkSession
object focusCrime extends App {
val spark = SparkSession.builder.appName("Data Analysis").master("local").getOrCreate()
val sContext = spark.sparkContext
val data = spark.read
.option("header", true)
.option("inferSchema", true)
.csv(StaticTool.DATE_DATA)
// 取回focusDate.scala中转储在hdfs中的数据
var crimeColumnDataSet = data.select("Crime").distinct()
crimeColumnDataSet.show(20)
println(crimeColumnDataSet.count())
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
+--------------------+
| Crime|
+--------------------+
|OFFENSE INVOLVING...|
|CRIMINAL SEXUAL A...|
| STALKING|
|PUBLIC PEACE VIOL...|
| OBSCENITY|
|NON-CRIMINAL (SUB...|
| ARSON|
| DOMESTIC VIOLENCE|
| GAMBLING|
| CRIMINAL TRESPASS|
| ASSAULT|
| NON - CRIMINAL|
|LIQUOR LAW VIOLATION|
| MOTOR VEHICLE THEFT|
| THEFT|
| BATTERY|
| ROBBERY|
| HOMICIDE|
| RITUALISM|
| PUBLIC INDECENCY|
+--------------------+
only showing top 20 rows
36
总共36种不同的犯罪类型.
Crime Summary(Spark SQL)
DataFrame内操作也行, 抱着入门框架的心态, 硬上Spark SQL吧
只看总的犯罪统计, 抓个靠前的十宗罪吧
这里留了点代码, 到时候往Hive里面写或者往MariaDB里面写, 换到pyspark画图方便些.
focusCrime.scala - 2
注意的是: 要使用
spark sql,dataframe或者rdd里面的东西要做成一个View, 就可以当成一个表做结构化查询了.
1
2
3
4
5
6
7
8
9
data.createOrReplaceTempView("t_CrimeDate")
val eachCrimeSummary = spark.
sql("select Crime, count(1) Occurs " +
"from t_CrimeDate " +
"group by Crime")
// For Writing in CSV or Hive DB in further PySpark Usage
// eachCrimeSummary.write.option("header", true).csv("")
eachCrimeSummary.orderBy(desc("Occurs")).show(10)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
+-------------------+-------+
| Crime| Occurs|
+-------------------+-------+
| THEFT|1522618| # 偷窃
| BATTERY|1321333| # 殴打
| CRIMINAL DAMAGE| 821509| # 破坏(刑事)
| NARCOTICS| 733993| # 毒品犯罪
| ASSAULT| 456288| # 攻击
| OTHER OFFENSE| 447617| # 其他侵犯
| BURGLARY| 406317| # 非法入侵
|MOTOR VEHICLE THEFT| 331980| # 盗窃车辆
| DECEPTIVE PRACTICE| 297519| # 诈骗
| ROBBERY| 270936| # 抢劫
+-------------------+-------+
Monthly Summary(Spark SQL)
抓一下按月分类的, 看看数据是否有特征, 如果有特征就可以尝试后续做图.
focusCrime.scala - 3
1
2
3
4
5
val groupByMonth = spark
.sql("select month(Month) NaturalMonth, count(1) CrimePerMonth " +
"from t_CrimeDate " +
"group by NaturalMonth")
groupByMonth.orderBy(desc("CrimePerMonth")).show(12)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
+------------+-------------+
|NaturalMonth|CrimePerMonth|
+------------+-------------+
| 7| 675041|
| 8| 668824|
| 5| 644421|
| 6| 641529|
| 9| 625696|
| 10| 620504|
| 3| 594688|
| 4| 593116|
| 1| 568404|
| 11| 553769|
| 12| 525734|
| 2| 500547|
+------------+-------------+
这里就有很明显的趋势了, 年中部分的犯罪数量明显比年尾年头高.
Prepare External Data
上次抓天气数据, 把2001年到今年, 每年的数据都抓下来了, 数据格式是Date, High, Low
1
2
3
4
5
6
7
8
9
10
11
12
13
mijazz@lenovo ~/pyProjects/.../weatherDataCsv master ±✚ ls
2001.csv 2003.csv 2005.csv 2007.csv 2009.csv 2011.csv 2013.csv 2015.csv 2017.csv 2019.csv
2002.csv 2004.csv 2006.csv 2008.csv 2010.csv 2012.csv 2014.csv 2016.csv 2018.csv 2020.csv
mijazz@lenovo ~/pyProjects/.../weatherDataCsv master ±✚ echo "Date,High,Low" > ./temperature.full.csv
mijazz@lenovo ~/pyProjects/.../weatherDataCsv master ±✚ cat ./*.csv >> ./temperature.full.csv
✘ mijazz@lenovo ~/pyProjects/.../weatherDataCsv master ±✚ head -n 3 ./temperature.full.csv
Date,High,Low
2001-01-01,24,5
2001-01-02,19,5
mijazz@lenovo ~/pyProjects/.../weatherDataCsv master ±✚ tail -n 3 ./temperature.full.csv
2020-11-21,48,36
2020-11-22,47,41
2020-11-23,46,33
现在可以将其放到hdfs里, 然后尝试在spark里交叉补充好气温信息. 为可视化做准备.
1
2
3
4
5
6
mijazz@lenovo ~/pyProjects/.../weatherDataCsv master ±✚ hdfs dfs -put ./temperature.full.csv /user/mijazz/chicagoData/temperature.full.csv
mijazz@lenovo ~/pyProjects/.../weatherDataCsv master ±✚ hdfs dfs -ls /user/mijazz/chicagoData
Found 3 items
drwxr-xr-x - mijazz supergroup 0 2020-11-30 21:16 /user/mijazz/chicagoData/dateDF.csv
-rw-r--r-- 1 mijazz supergroup 1701238602 2020-11-30 15:43 /user/mijazz/chicagoData/originCrimeData.csv
-rw-r--r-- 1 mijazz supergroup 123272 2020-11-30 23:37 /user/mijazz/chicagoData/temperature.full.csv
Data Practicing-EP5
Get Weather Data
StaticTool.java - +(Add Row)
1
+ public static final String WEATHER_DATA = DATA_PATH + "temperature.full.csv";
MergeWeather.scala - 1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package edu.zstu.mijazz.sparklearn1
import org.apache.spark.sql.SparkSession
object MergeWeather extends App{
val spark = SparkSession.builder.appName("Data Analysis").master("local").getOrCreate()
val sContext = spark.sparkContext
val data = spark.read
.option("header", true)
.option("inferSchema", false)
.csv(StaticTool.WEATHER_DATA)
data.printSchema()
data.show(3)
}
1
2
3
4
5
6
7
8
9
10
11
12
13
root
|-- Date: string (nullable = true)
|-- High: string (nullable = true)
|-- Low: string (nullable = true)
+----------+----+---+
| Date|High|Low|
+----------+----+---+
|2001-01-01| 24| 5|
|2001-01-02| 19| 5|
|2001-01-03| 28| 7|
+----------+----+---+
only showing top 3 rows
inferSchema==false因为在EP4dataFrame中有一列的Day的类型本就是string, 这里如果给了true, 就被内转成timestamp了, 对后续sql不算太方便.
Merge them Together
在EP4中我曾经通过createOrReplaceTempView()来创建了一张临时表, 但是这张表的生命周期是绑定在SparkSession上的, 现在我换了一个Session, 现在采用createGlobalTempView()
详细见文章总结.
focusDate.scala - (- means delete row, + means add row)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- data.createOrReplaceTempView("t_CrimeDate")
+ data.createOrReplaceGlobalTempView("t_CrimeDate")
val eachCrimeSummary = spark.
sql("select Crime, count(1) Occurs " +
- "from t_CrimeDate " +
+ "from global_temp.t_CrimeDate " +
"group by Crime")
val groupByMonth = spark
.sql("select month(Month) NaturalMonth, count(1) CrimePerMonth " +
- "from t_CrimeDate " +
+ "from global_temp.t_CrimeDate " +
"group by NaturalMonth")
通过前面生成了globalTempView之后, 就可以在另一个Session中来通过global_temp.表名来访问了.
这里采用spark sql来进行数据合并. 先把表做出来
MergeWeather.scala - 2
1
data.createOrReplaceGlobalTempView("t_weatherData")
先看一下两张表的Schema关联长什么样
1
2
3
4
5
6
7
8
9
10
11
12
13
// global_temp.t_CrimeDate
root
|-- Crime: string (nullable = true)
|-- Year: integer (nullable = true)
|-- TimeStamp: timestamp (nullable = true)
|-- Month: string (nullable = true)
|-- Day: timestamp (nullable = true)
|-- Hour: integer (nullable = true)
// global_temp.t_weatherData
root
|-- Date: string (nullable = true)
|-- High: string (nullable = true)
|-- Low: string (nullable = true)
global_temp.t_CrimeDate.Day <==> global_temp.t_weatherData.Date
High, Low Join上
MergeWeather.scala - 3
1
2
3
4
5
6
val mergedData = spark.newSession()
.sql("select C.Crime, C.Year, C.TimeStamp, C.Month, C.Day, W.High, W.Low C.Location " +
"from global_temp.t_CrimeDate C, global_temp.t_weatherData W " +
"where C.Day = W.Date")
mergedData.printSchema()
mergedData.show(3)
1
2
3
4
5
6
7
8
+-------------------+----+-------------------+-------+-------------------+----+---+---------+
| Crime|Year| TimeStamp| Month| Day|High|Low| Location|
+-------------------+----+-------------------+-------+-------------------+----+---+---------+
| DECEPTIVE PRACTICE|2001|2001-01-01 11:00:00|2001-01|2001-01-01 00:00:00| 24| 5|RESIDENCE|
|CRIM SEXUAL ASSAULT|2017|2017-10-08 03:00:00|2017-10|2017-10-08 00:00:00| 78| 54|RESIDENCE|
| BURGLARY|2017|2017-03-28 02:00:00|2017-03|2017-03-28 00:00:00| 50| 36| OTHER|
+-------------------+----+-------------------+-------+-------------------+----+---+---------+
only showing top 3 rows
所以现在每条犯罪记录都有了当天的天气信息了.
但是温标是华氏温标, (F - 32) / 1.8 = C. 用DataFrame来做就行, 虽然当时SQL导入的时候也可以这样做.
MergeWeather.scala - 4
1
2
3
4
5
6
7
8
mergedData = mergedData
.withColumn("HighC", round(col("High").cast("float").-(32.0)./(1.8), 2))
.withColumn("LowC", round(col("Low").cast("float").-(32.0)./(1.8), 2))
.drop("High")
.drop("Low")
mergedData.printSchema()
mergedData.show(3)
1
2
3
4
5
6
7
8
+-------------------+----+-------------------+-------+-------------------+---------+-----+-----+
| Crime|Year| TimeStamp| Month| Day| Location|HighC| LowC|
+-------------------+----+-------------------+-------+-------------------+---------+-----+-----+
| DECEPTIVE PRACTICE|2001|2001-01-01 11:00:00|2001-01|2001-01-01 00:00:00|RESIDENCE|-4.44|-15.0|
|CRIM SEXUAL ASSAULT|2017|2017-10-08 03:00:00|2017-10|2017-10-08 00:00:00|RESIDENCE|25.56|12.22|
| BURGLARY|2017|2017-03-28 02:00:00|2017-03|2017-03-28 00:00:00| OTHER| 10.0| 2.22|
+-------------------+----+-------------------+-------+-------------------+---------+-----+-----+
only showing top 3 rows
MergeWeather.scala - 5
reparition(1)
Returns a new Dataset partitioned by the given partitioning expressions into
numPartitions. The resulting Dataset is hash partitioned.
1
2
3
4
5
mergedData
.repartition(1)
.write
.option("header", true)
.csv(StaticTool.DATA_PATH + "forPySpark.csv")
Data Practicing-EP6
Introduce pyspark
Scala和Python下对于Spark的操作还是有很多相似的地方的.
迁移到PySpark下, 因为toPandas和collect() => List这两个pyspark独有的特性, 使得可视化较Scala下方便.
不过要注意的是Spark.DataFrame和Pandas.DataFrame是两个完全不同的东西. 不过也很好理解, 鉴于这一次实验我是故意避开不使用Pandas的东西的.
假设有如下案例吧
1
2
3
4
5
6
7
8
9
import random
def rInt():
return random.randint(1, 100)
def rStr():
return random.choice('I Just Dont Want To Use DataFrame From Pandas'.split(' '))
def rRow():
return [rInt(), rStr()]
print(rRow())
1
2
[66, 'Pandas']
[35, 'Just']
每次调用rRow()都会返回一个List, 也就是sparkDataFrame中的一行数据.
通过Scala中可以知道, SparkSession控制每次的Spark会话, 而他也提供一个方法来创建会话.
parallelize()用于RDD, toDF()会把RDD数据转成Spark.DataFrame
1
2
3
4
5
6
7
8
9
10
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master('local').appName('Learn Pyspark').getOrCreate()
sc = spark.sparkContext
exampleSparkDataFrame = \
sc.parallelize([rRow() for _ in range(5)]).toDF(("Number", "Word"))
exampleSparkDataFrame.show()
print(type(exampleSparkDataFrame))
1
2
3
4
5
6
7
8
9
10
11
+------+---------+
|Number| Word|
+------+---------+
| 60|DataFrame|
| 43| Just|
| 85| Want|
| 64| Use|
| 52|DataFrame|
+------+---------+
<class 'pyspark.sql.dataframe.DataFrame'>
也可以很方便的通过toPandas()方式转换.
1
2
3
examplePandasDataFrame = exampleSparkDataFrame.toPandas()
examplePandasDataFrame.info()
print(type(examplePandasDataFrame))
1
2
3
4
5
6
7
8
9
RangeIndex: 5 entries, 0 to 4
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Number 5 non-null int64
1 Word 5 non-null object
dtypes: int64(1), object(1)
memory usage: 208.0+ bytes
<class 'pandas.core.frame.DataFrame'>
当想取列时, select()选择列, collect()将其从远端的Spark.DataFrame拉回本地Python.
1
2
print(exampleSparkDataFrame.select('Number').collect())
print(exampleSparkDataFrame.select('Word').collect())
1
2
[Row(Number=6), Row(Number=16), Row(Number=50), Row(Number=53), Row(Number=51)]
[Row(Word='Just'), Row(Word='To'), Row(Word='From'), Row(Word='Just'), Row(Word='Pandas')]
假如你需要拿spark.DataFrame中的列来画图, 如下几种方法都是一样的.
1
2
3
4
5
6
7
eg = [0 for _ in range(4)]
eg[0] = list(exampleSparkDataFrame.toPandas()['Number'])
eg[1] = exampleSparkDataFrame.select('Number').rdd.flatMap(lambda x: x).collect()
eg[2] = exampleSparkDataFrame.select('Number').rdd.map(lambda x: x[0]).collect()
eg[3] = [x[0] for x in exampleSparkDataFrame.select('Number').collect()]
for example in eg:
print(example)
1
2
3
4
[95, 56, 54, 61, 58]
[95, 56, 54, 61, 58]
[95, 56, 54, 61, 58]
[95, 56, 54, 61, 58]
但是不推荐eg[0]对应的方法, 他是将整个spark.DataFrame从远端取回来, 如果使用的是集群, 或者数据量比较大的话, 交给本地的python将其转为Pandas.DataFrame. 而其余几种, 而是交给spark处理过后, 单独剥离一列值进行返回.
rdd内实现的操作这里不详述.
Start to Use PySpark
EP5中拿出了两批数据, 分别是forPyspark.csv和temperature.full.csv
先做以下导入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# -*- coding: utf-8 -*-
# @Author : MijazzChan
# Python Version == 3.8.6
import os
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
import pylab as plot
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, round
plt.rcParams['figure.dpi'] = 150
plt.rcParams['savefig.dpi'] = 150
sns.set(rc={"figure.dpi": 150, 'savefig.dpi': 150})
DATA_PATH = "hdfs://localhost:9000/user/mijazz/chicagoData/"
Something irrelevant
1
2
3
4
5
6
7
8
9
10
11
12
13
14
spark = SparkSession.builder.master('local').appName('Data Visualization').getOrCreate()
weatherData = spark.read\
.option('header', True)\
.option('inferSchema', True)\
.csv(DATA_PATH + 'temperature.full.csv')
# 转摄氏度
weatherData = weatherData\
.withColumn('HighC', round((col('High').cast('float') - 32.0) / 1.8, 2))\
.withColumn('LowC', round((col('Low').cast('float') - 32.0) / 1.8, 2))\
.drop('High')\
.drop('Low')
weatherData.createOrReplaceGlobalTempView('v_Weather')
weatherData.describe().show()
1
2
3
4
5
6
7
8
9
+-------+----------+------------------+------------------+
|summary| Date| HighC| LowC|
+-------+----------+------------------+------------------+
| count| 7267| 7267| 7267|
| mean| null|15.352508600522908| 5.617067565708001|
| stddev| null|11.811098684239695|10.534155955862133|
| min|2001-01-01| -23.33| -30.56|
| max|2020-11-23| 39.44| 27.78|
+-------+----------+------------------+------------------+
拿到的数据集, 2001-01-01年到2020-11-23总平均最高气温是15.35, 总平均最低气温是5.62
Full Coverage
对着整个天气数据集画个图呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
xDays = weatherData.select('Date').rdd.flatMap(lambda x: x).collect()
yFullHigh = weatherData.select('HighC').rdd.flatMap(lambda x: x).collect()
yFullLow = weatherData.select('LowC').rdd.flatMap(lambda x: x).collect()
fig, axs = plt.subplots(2, 1)
axs[0].plot(xDays, yFullHigh)
axs[0].set_title('High Temp Full Coverage in Chicago City, 2001-2020')
axs[0].set_xlabel('Year')
axs[0].set_xticks([])
axs[0].set_ylabel('Temperature Celsius')
axs[1].plot(xDays, yFullLow)
axs[1].set_title('High Temp Full Coverage in Chicago City, 2001-2020')
axs[1].set_xlabel('Year')
axs[1].set_xticks([])
axs[1].set_ylabel('Temperature Celsius')
plt.show()
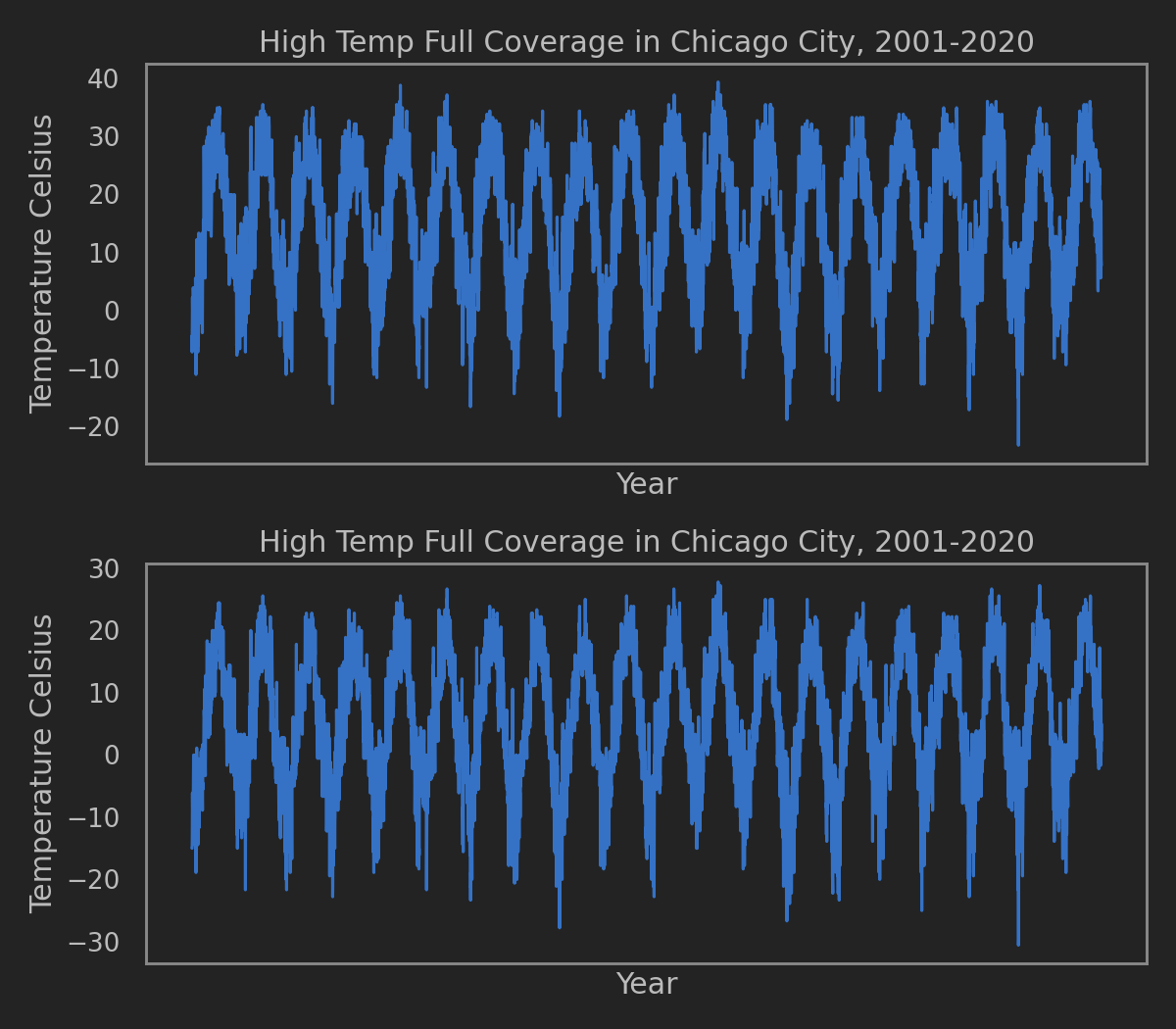
仿佛看不出来什么规律. 说好的全球变暖呢
Annual Summary
那就按年平均画个图吧
1
2
3
4
5
6
annualData = \
spark.sql('SELECT year(Date) Annual, round(avg(HighC), 2) avgHigh, round(avg(LowC), 2) avgLow '
'FROM global_temp.v_Weather '
'GROUP BY year(Date) ')\
.orderBy(asc('Annual'))
annualData.show(20)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
+------+-------+------+
|Annual|avgHigh|avgLow|
+------+-------+------+
| 2001| 15.39| 5.49|
| 2002| 15.37| 5.62|
| 2003| 14.63| 4.24|
| 2004| 14.98| 4.88|
| 2005| 15.87| 5.53|
| 2006| 15.9| 6.31|
| 2007| 15.6| 5.84|
| 2008| 14.25| 4.38|
| 2009| 14.05| 4.58|
| 2010| 15.66| 6.07|
| 2011| 15.04| 5.85|
| 2012| 17.73| 7.3|
| 2013| 14.43| 4.68|
| 2014| 13.66| 3.76|
| 2015| 15.02| 5.26|
| 2016| 15.97| 6.57|
| 2017| 16.27| 6.59|
| 2018| 15.12| 6.08|
| 2019| 14.44| 5.31|
| 2020| 17.91| 8.26|
+------+-------+------+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
fig, axs = plt.subplots(2, 1)
xYear = annualData.select('Annual').collect()
yAvgHigh = annualData.select('avgHigh').collect()
yAvgLow = annualData.select('avgLow').collect()
axs[0].plot(xYear, yAvgHigh)
axs[0].set_title('Average High Temp in Chicago City')
axs[0].set_xlabel('Year')
axs[0].set_ylabel('Temperature Celsius')
axs[1].plot(xYear, yAvgLow)
axs[1].set_title('Average Low Temp in Chicago City')
axs[1].set_xlabel('Year')
axs[1].set_ylabel('Temperature Celsius')
plt.show()
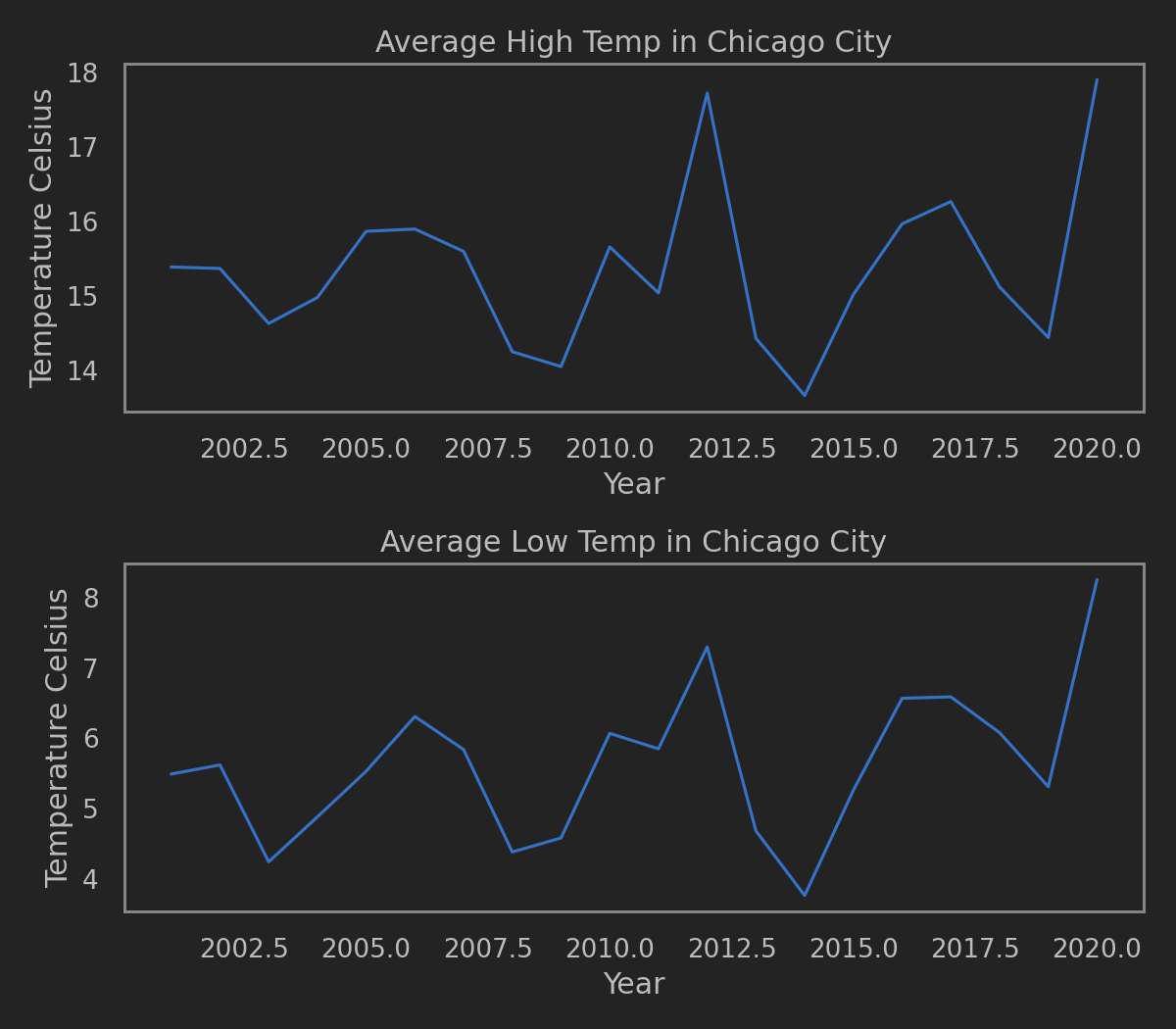
现在是能看出一些趋势了.
Plot Some Data
Some Acknowledgement
该函数用于快速返回指定spark.DataFrame的列.
1
2
def column2List(dataFrame, column):
return dataFrame.select(column).rdd.flatMap(lambda x: x).collect()
而且拿dataFrame中的数据, 有各种方法, 此处就以犯罪数据排名作为例子.
1
2
3
4
5
6
7
8
9
root
|-- Crime: string (nullable = true)
|-- Year: integer (nullable = true)
|-- TimeStamp: timestamp (nullable = true)
|-- Month: string (nullable = true)
|-- Day: timestamp (nullable = true)
|-- Location: string (nullable = true)
|-- HighC: double (nullable = true)
|-- LowC: double (nullable = true)
想摘取数据进行分析
DataFrame Approach
1
2
3
4
5
crimeRankPlotData = fullData.select('Crime')\
.groupBy('Crime')\
.count()\
.orderBy(desc('count'))\
.limit(15)
Spark SQL Approach
1
2
3
4
5
6
fullData.createGlobalTempView('v_Crime')
crimeRankPlotData = spark.sql('SELECT Crime, count(1) crimeCount '
'FROM global_temp.v_Crime '
'GROUP BY Crime '
'ORDER BY crimeCount DESC '
'LIMIT 15')
RDD Appraoch
1
fullData.rdd.countByKey().items() # -> dict
Crime Rank Plot
记得在EP4中, 拿出来看过犯罪数据的排名. 做个前15的BarPlot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
fullData = spark.read\
.option('header', True)\
.option('inferSchema', True)\
.csv(DATA_PATH + 'forPySpark.csv').cache()
crimeRankPlotData = fullData.select('Crime')\
.groupBy('Crime')\
.count()\
.orderBy(desc('count'))\
.limit(15)
plt.figure()
plt.barh(column2List(crimeRankPlotData, 'Crime'), column2List(crimeRankPlotData, 'count'))
plt.xlabel('Crime Count')
plt.ylabel('Crime Type')
plt.title('TOP 15 Crime Count')
plt.show()
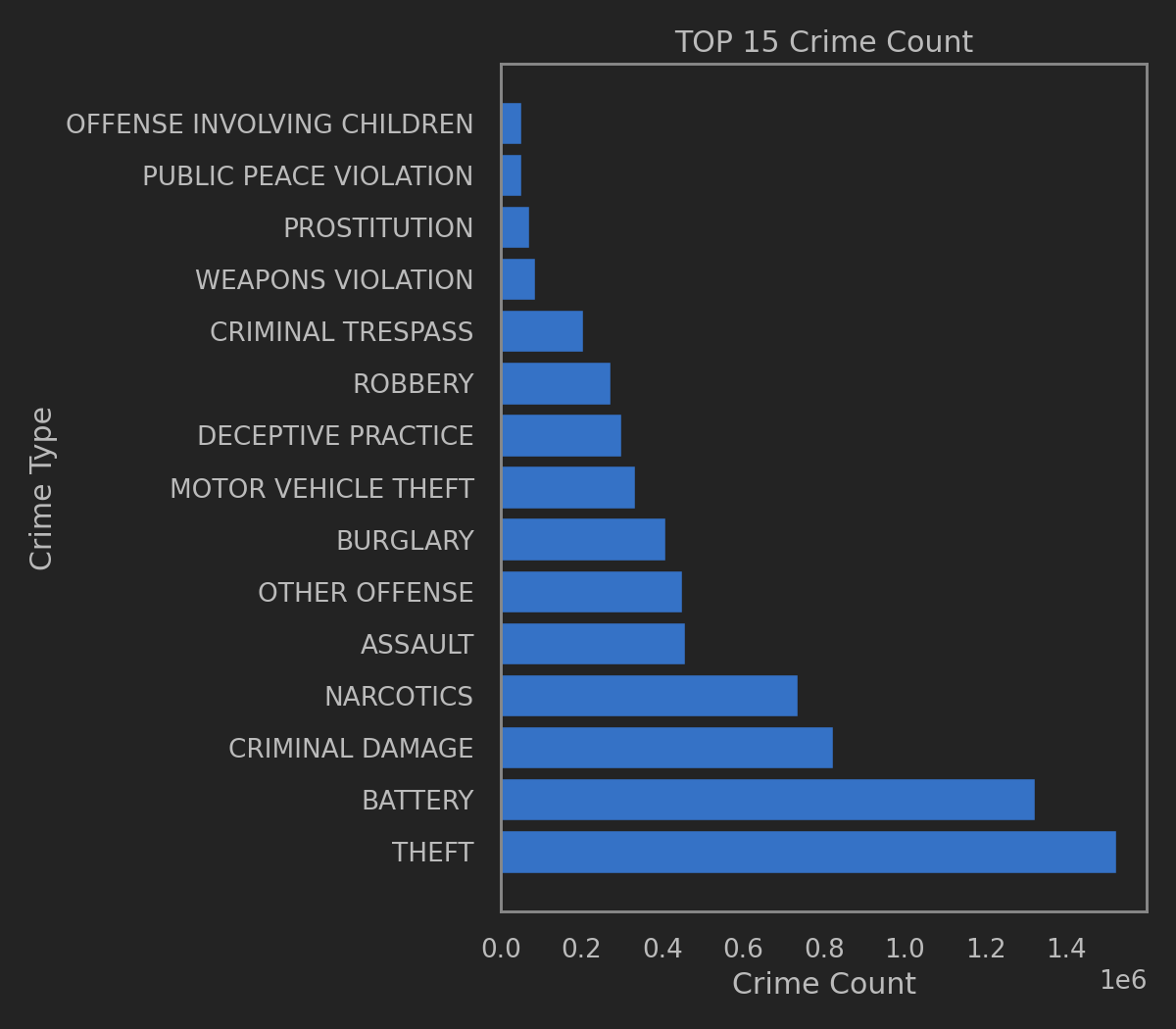
Location Distribution Plot
1
2
3
4
5
6
7
8
9
10
11
12
13
locationRankPlotData = fullData.select('Location')\
.groupBy('Location')\
.count()\
.orderBy(desc('count'))
locationRankPlotData.show(20)
plt.figure()
tmp1 = column2List(locationRankPlotData, 'Location')
tmp2 = column2List(locationRankPlotData, 'count')
plt.barh(tmp1[:15], tmp2[:15])
plt.xlabel('Crime Count')
plt.ylabel('Crime Type')
plt.title('Location Distribution of Crimes')
plt.show()
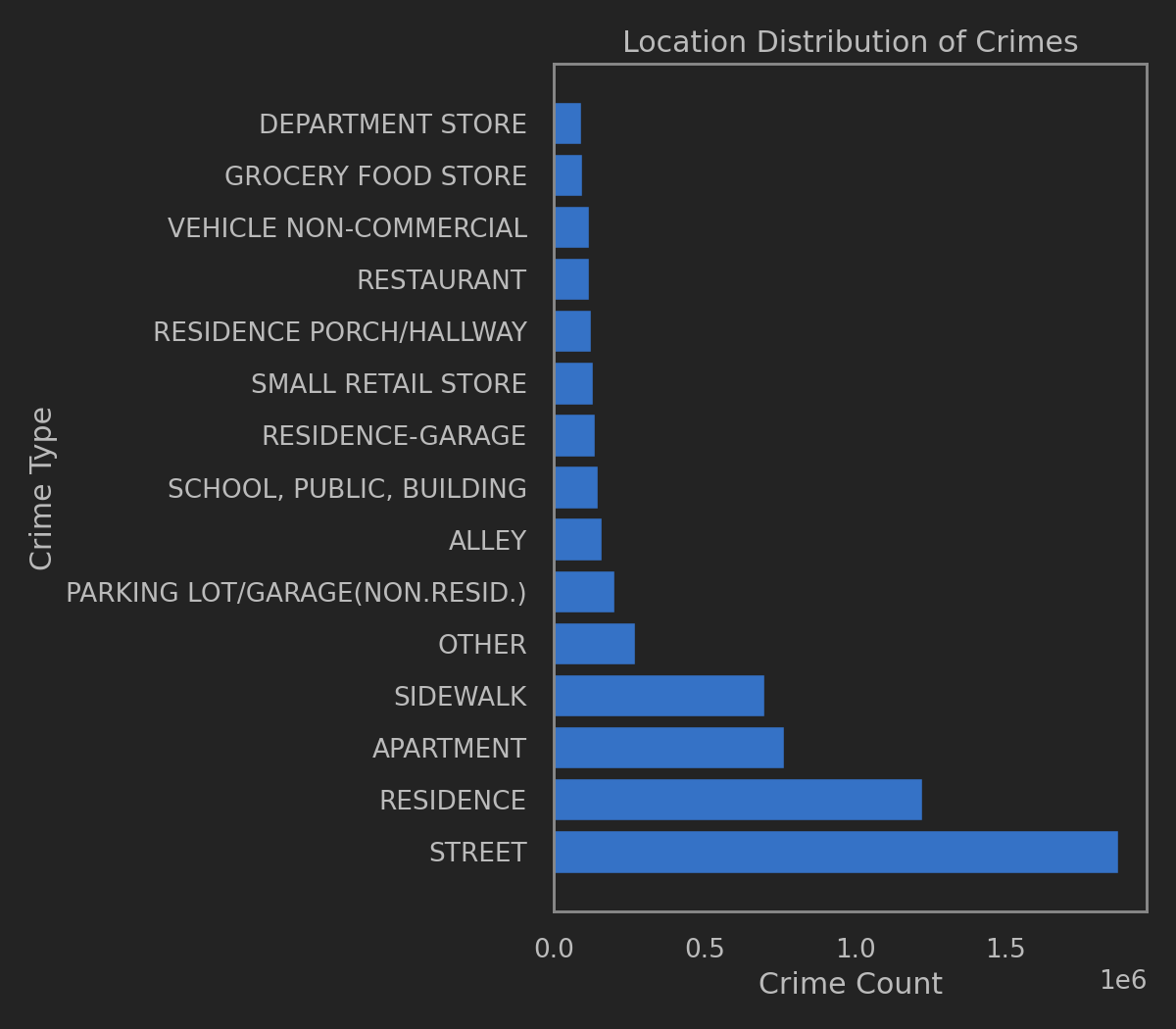
Annual Crime Count Plot
1
2
3
4
5
6
7
8
9
10
11
12
crimePerYear = spark.sql('SELECT year(C.TimeStamp) Annual, count(1) CrimePerYear '
'FROM global_temp.v_Crime C '
'GROUP BY year(C.TimeStamp) '
'ORDER BY Annual ASC')
crimePerYear.show(20)
plt.figure()
# 2020年的数据不齐, 去掉
plt.plot(column2List(crimePerYear, 'Annual')[:19], column2List(crimePerYear, 'CrimePerYear')[:19])
plt.title('Crime Count Per Year in Chicago City')
plt.xlabel('Year')
plt.ylabel('Crime Count')
plt.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
+------+------------+
|Annual|CrimePerYear|
+------+------------+
| 2001| 485783|
| 2002| 486764|
| 2003| 475962|
| 2004| 469395|
| 2005| 453735|
| 2006| 448138|
| 2007| 437041|
| 2008| 427099|
| 2009| 392770|
| 2010| 370395|
| 2011| 351878|
| 2012| 336137|
| 2013| 307299|
| 2014| 275545|
| 2015| 264449|
| 2016| 269443|
| 2017| 268675|
| 2018| 268222|
| 2019| 260318|
| 2020| 163225|
+------+------------+
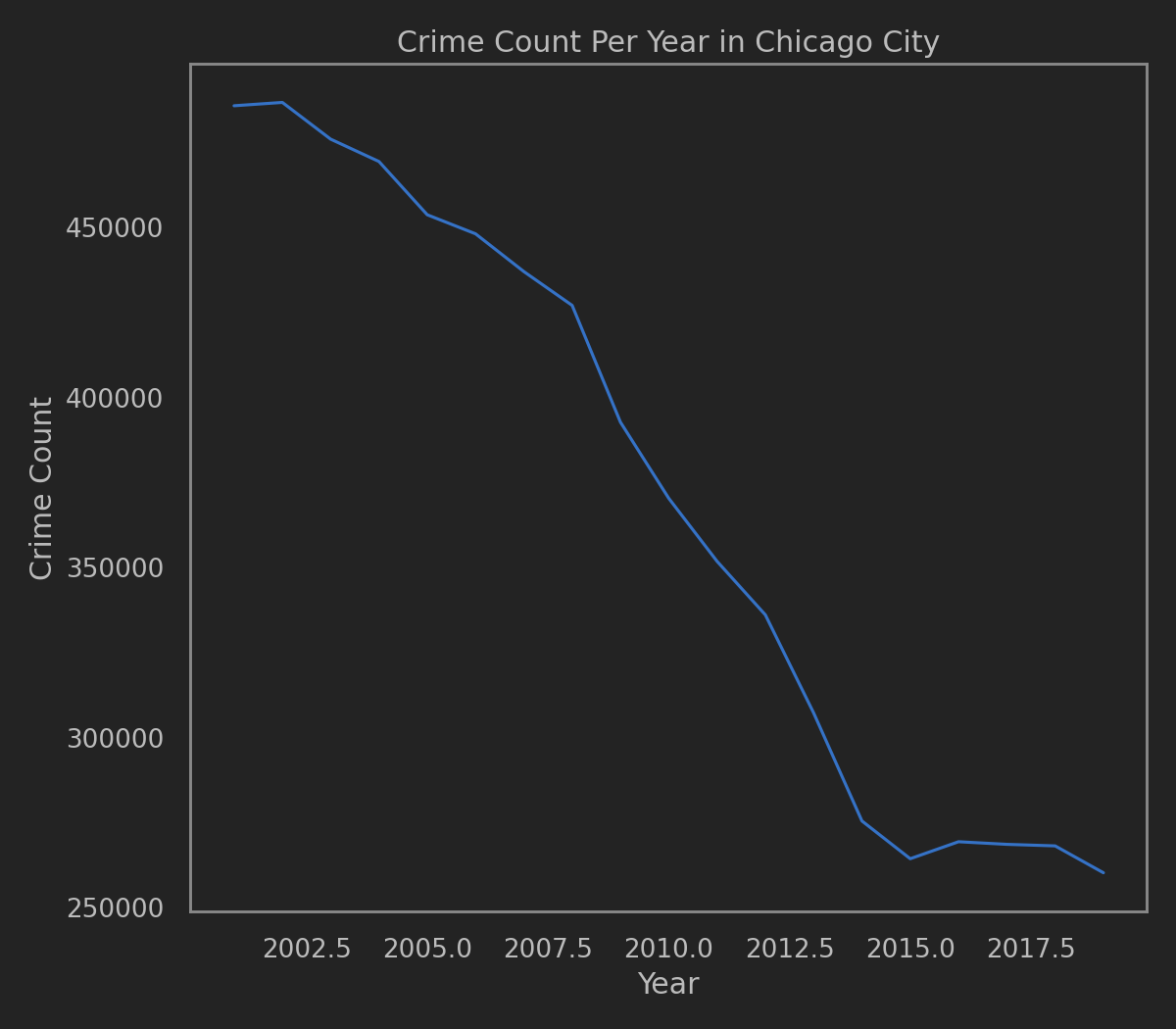
Data Practicing-EP7
Visualization in Python
Pandas和notebook一起用, 在这个先被Spark处理过的几百万行的数据集上做可视化还是感觉方便些.
先做个依赖导入和数据清洗吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# -*- coding: utf-8 -*-
# Python Version == 3.8.6
import os
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
plt.rcParams['figure.dpi'] = 150
plt.rcParams['savefig.dpi'] = 150
sns.set(rc={"figure.dpi": 150, 'savefig.dpi': 150})
from jupyterthemes import jtplot
jtplot.style(theme='monokai', context='notebook', ticks=True, grid=False)
fullData = pd.read_csv('~/devEnvs/chicagoCrimeData.csv', encoding='utf-8')
fullData.info()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
/home/mijazz/devEnvs/pyvenv/lib/python3.8/site-packages/IPython/core/interactiveshell.py:3062: DtypeWarning: Columns (21) have mixed types.Specify dtype option on import or set low_memory=False.
has_raised = await self.run_ast_nodes(code_ast.body, cell_name,
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7212273 entries, 0 to 7212272
Data columns (total 22 columns):
# Column Dtype
--- ------ -----
0 ID int64
1 Case Number object
2 Date object
3 Block object
4 IUCR object
5 Primary Type object
6 Description object
7 Location Description object
8 Arrest bool
9 Domestic bool
10 Beat int64
11 District float64
12 Ward float64
13 Community Area float64
14 FBI Code object
15 X Coordinate float64
16 Y Coordinate float64
17 Year int64
18 Updated On object
19 Latitude float64
20 Longitude float64
21 Location object
dtypes: bool(2), float64(7), int64(3), object(10)
memory usage: 1.1+ GB
1
fullData.head(5)
| ID | Case Number | Date | Block | IUCR | Primary Type | Description | Location Description | Arrest | Domestic | ... | Ward | Community Area | FBI Code | X Coordinate | Y Coordinate | Year | Updated On | Latitude | Longitude | Location | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11034701 | JA366925 | 01/01/2001 11:00:00 AM | 016XX E 86TH PL | 1153 | DECEPTIVE PRACTICE | FINANCIAL IDENTITY THEFT OVER $ 300 | RESIDENCE | False | False | ... | 8.0 | 45.0 | 11 | NaN | NaN | 2001 | 08/05/2017 03:50:08 PM | NaN | NaN | NaN |
| 1 | 11227287 | JB147188 | 10/08/2017 03:00:00 AM | 092XX S RACINE AVE | 0281 | CRIM SEXUAL ASSAULT | NON-AGGRAVATED | RESIDENCE | False | False | ... | 21.0 | 73.0 | 02 | NaN | NaN | 2017 | 02/11/2018 03:57:41 PM | NaN | NaN | NaN |
| 2 | 11227583 | JB147595 | 03/28/2017 02:00:00 PM | 026XX W 79TH ST | 0620 | BURGLARY | UNLAWFUL ENTRY | OTHER | False | False | ... | 18.0 | 70.0 | 05 | NaN | NaN | 2017 | 02/11/2018 03:57:41 PM | NaN | NaN | NaN |
| 3 | 11227293 | JB147230 | 09/09/2017 08:17:00 PM | 060XX S EBERHART AVE | 0810 | THEFT | OVER $500 | RESIDENCE | False | False | ... | 20.0 | 42.0 | 06 | NaN | NaN | 2017 | 02/11/2018 03:57:41 PM | NaN | NaN | NaN |
| 4 | 11227634 | JB147599 | 08/26/2017 10:00:00 AM | 001XX W RANDOLPH ST | 0281 | CRIM SEXUAL ASSAULT | NON-AGGRAVATED | HOTEL/MOTEL | False | False | ... | 42.0 | 32.0 | 02 | NaN | NaN | 2017 | 02/11/2018 03:57:41 PM | NaN | NaN | NaN |
5 rows × 22 columns
1
2
fullData.drop_duplicates(subset=['ID', 'Case Number'], inplace=True)
fullData.drop(['Case Number', 'IUCR','Updated On','Year', 'FBI Code', 'Beat','Ward','Community Area', 'Location'], inplace=True, axis=1)
1
fullData['Location Description'].describe()
1
2
3
4
5
count 7204883
unique 214
top STREET
freq 1874164
Name: Location Description, dtype: object
1
fullData['Description'].describe()
1
2
3
4
5
count 7212273
unique 532
top SIMPLE
freq 849119
Name: Description, dtype: object
1
fullData['Primary Type'].describe()
1
2
3
4
5
count 7212273
unique 36
top THEFT
freq 1522618
Name: Primary Type, dtype: object
可以看到这三列的其中两列, Location Description和Description有许多Unique值, 我们只取数量多的, 这里只取计数为前20的作为大类以做特征分析, 其他的归为杂类.
1
2
3
locationDescription20Except = list(fullData['Location Description'].value_counts()[20:].index)
# 用loc把数据砍掉
fullData.loc[fullData['Location Description'].isin(locationDescription20Except), fullData.columns=='Location Description'] = 'OTHER'
1
2
3
description20Except = list(fullData['Description'].value_counts()[20:].index)
# 用loc把数据砍掉
fullData.loc[fullData['Description'].isin(description20Except) , fullData.columns=='Description'] = 'OTHER'
之前在spark中已经看到犯罪数量是36种, 并且数量从2001年到现在是逐年减少的. 但是只有每年的统计, 这里尝试作做rolling sum. 也就是每个取样点的横坐标对应一个日期, 纵坐标对应(当前日期-364天 ~ 当天)的犯罪数量和.
先把Date换成Datetime
1
fullData.Date = pd.to_datetime(fullData.Date, format='%m/%d/%Y %I:%M:%S %p')
做Resample要有Index, 日期做了cast之后就行.
1
2
3
4
5
fullData.index = pd.DatetimeIndex(fullData.Date)
fullData.resample('D').size().rolling(365).sum().plot()
plt.xlabel('Days')
plt.ylabel('Crimes Count')
plt.show()
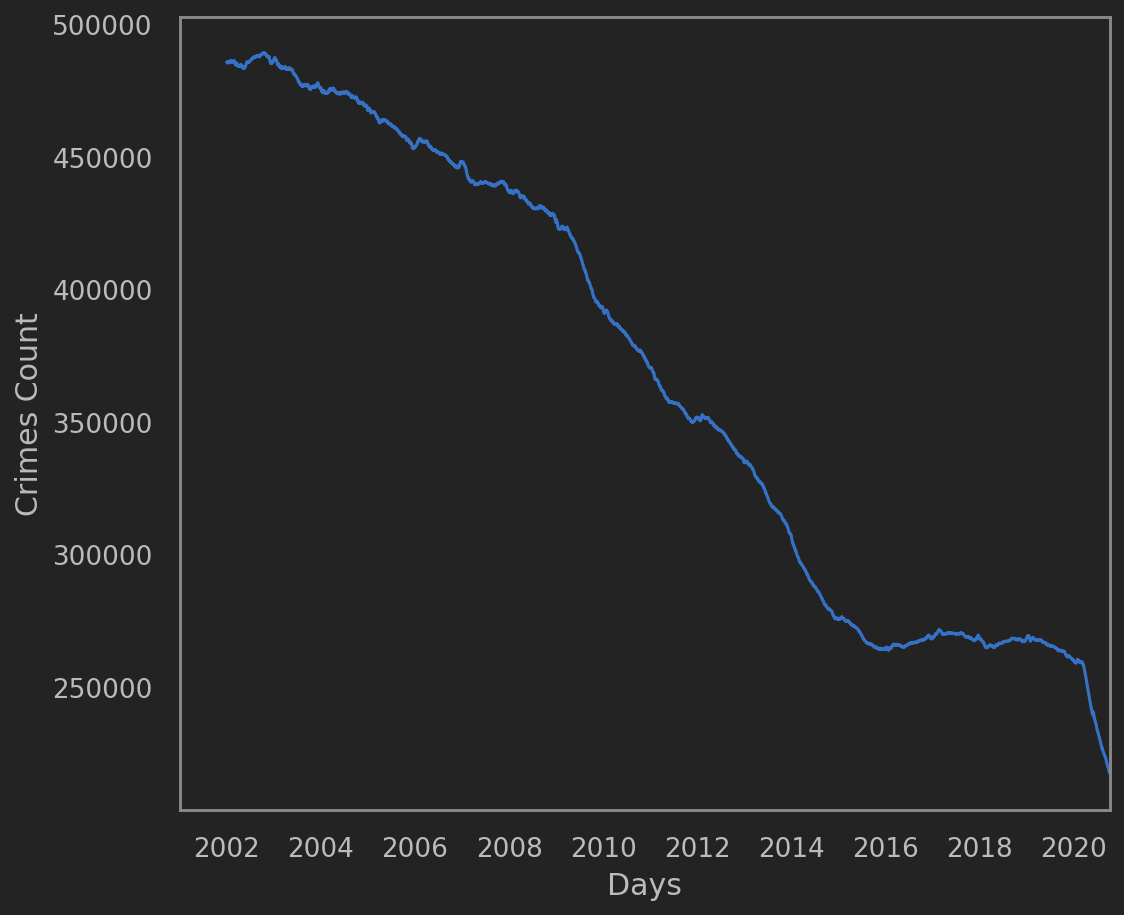
可以看到rolling sum是在稳步减少的.
现在分犯罪种类Primary Type来作图.
1
2
3
eachCrime = fullData.pivot_table('ID', aggfunc=np.size, columns='Primary Type', index=fullData.index.date, fill_value=0)
eachCrime.index = pd.DatetimeIndex(eachCrime.index)
tmp = eachCrime.rolling(365).sum().plot(figsize=(12, 60), subplots=True, layout=(-1, 2), sharex=False, sharey=False)
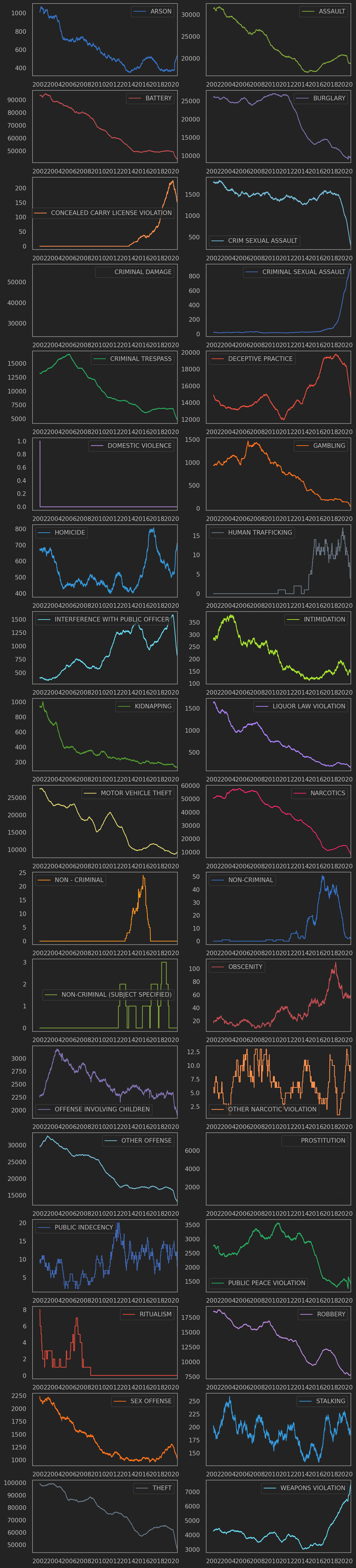
这里看到了一些无用的数据, 有些犯罪种类甚至近20年来发生不超过千次, 砍掉犯罪数量非前20的犯罪种类, 只留下前20的种类再做一个rolling sum.
并且留意到NON-CRIMINAL和NON - CRIMINAL两个类重复, 砍掉. 并也将其变为OTHER
1
2
crime20Except = list(fullData['Primary Type'].value_counts()[20:].index)
fullData.loc[fullData['Primary Type'].isin(crime20Except), fullData.columns=='Primary Type'] = 'OTHER'
1
2
fullData.loc[fullData['Primary Type'] == 'NON-CRIMINAL', fullData.columns=='Primary Type'] = 'OTHER'
fullData.loc[fullData['Primary Type'] == 'NON - CRIMINAL', fullData.columns=='Primary Type'] = 'OTHER'
1
2
3
eachCrime = fullData.pivot_table('ID', aggfunc=np.size, columns='Primary Type', index=fullData.index.date, fill_value=0)
eachCrime.index = pd.DatetimeIndex(eachCrime.index)
tmp = eachCrime.rolling(365).sum().plot(figsize=(12, 60), subplots=True, layout=(-1, 2), sharex=False, sharey=False)

数据处理完之后, 明显能够看出来, 基本的犯罪种类的数量的确是在下降的, 但是有两个WEAPONS VIOLATION和INTERFERENCE WITH PUBLIC OFFICER在逆势上涨.
Data Practicing-EP8
基于日期的话, 因为有index的缘故, 按日分类和按月分类都较为方便.
1
2
3
4
5
days = ['Mon','Tue','Wed', 'Thur', 'Fri', 'Sat', 'Sun']
fullData.groupby([fullData.index.dayofweek]).size().plot(kind='barh')
plt.yticks(np.arange(7), days)
plt.xlabel('Crime Counts')
plt.show()
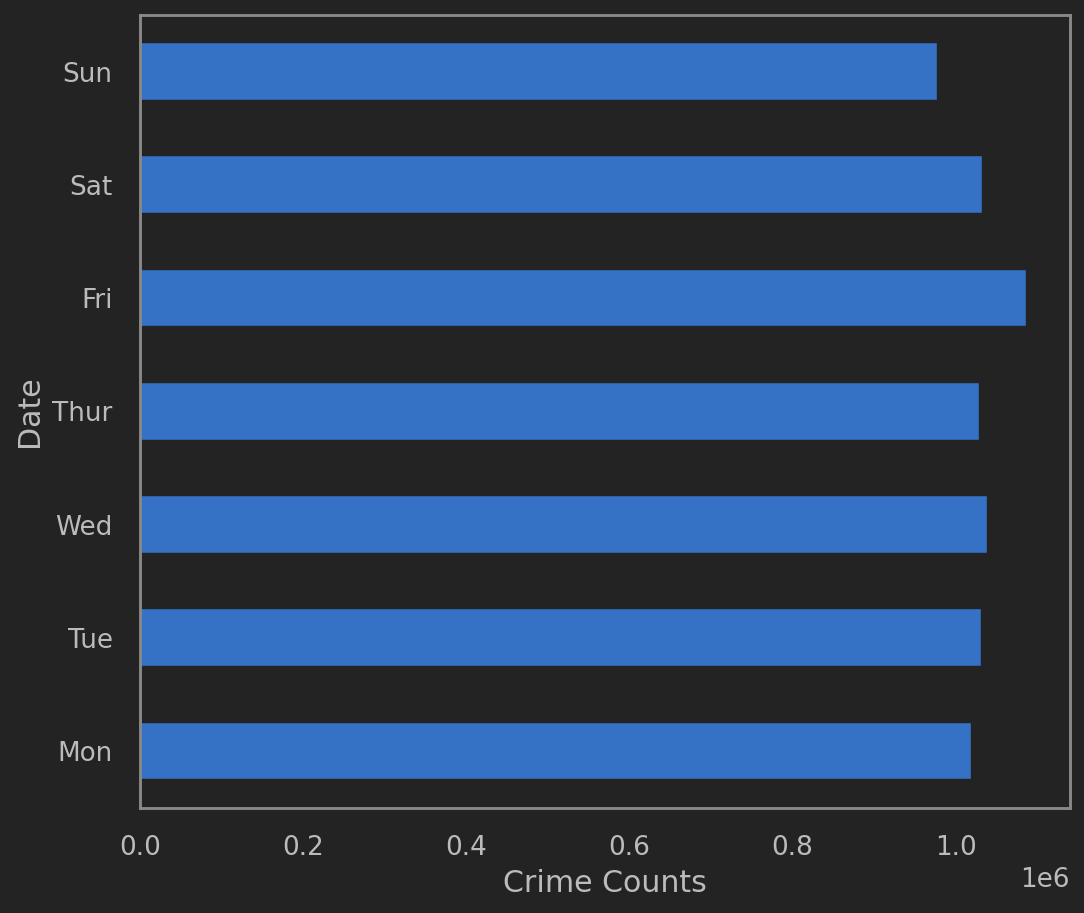
周五的贡献由为突出
1
2
3
4
fullData.groupby([fullData.index.month]).size().plot(kind='barh')
plt.ylabel('Month')
plt.xlabel('Crime Counts')
plt.show()
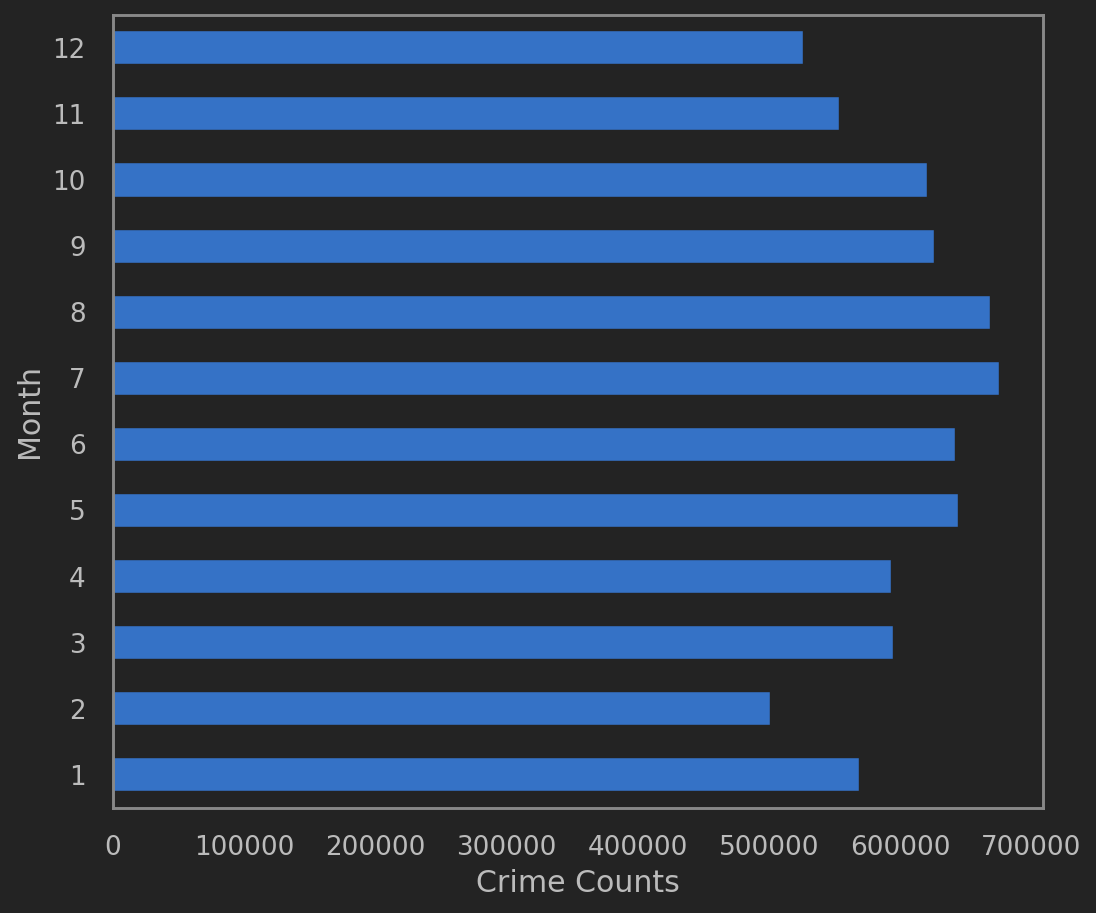
按月分类可以看到主要集中于夏季.
在EP7里,
Location Description已经被减少至20个, 排名靠后的被修改成OTHERS了
对犯罪发生地点的归类.
1
2
3
4
fullData.groupby([fullData['Location Description']]).size().sort_values(ascending=True).plot(kind='barh')
plt.ylabel('Crime Location')
plt.xlabel('Crimes Count')
plt.show()
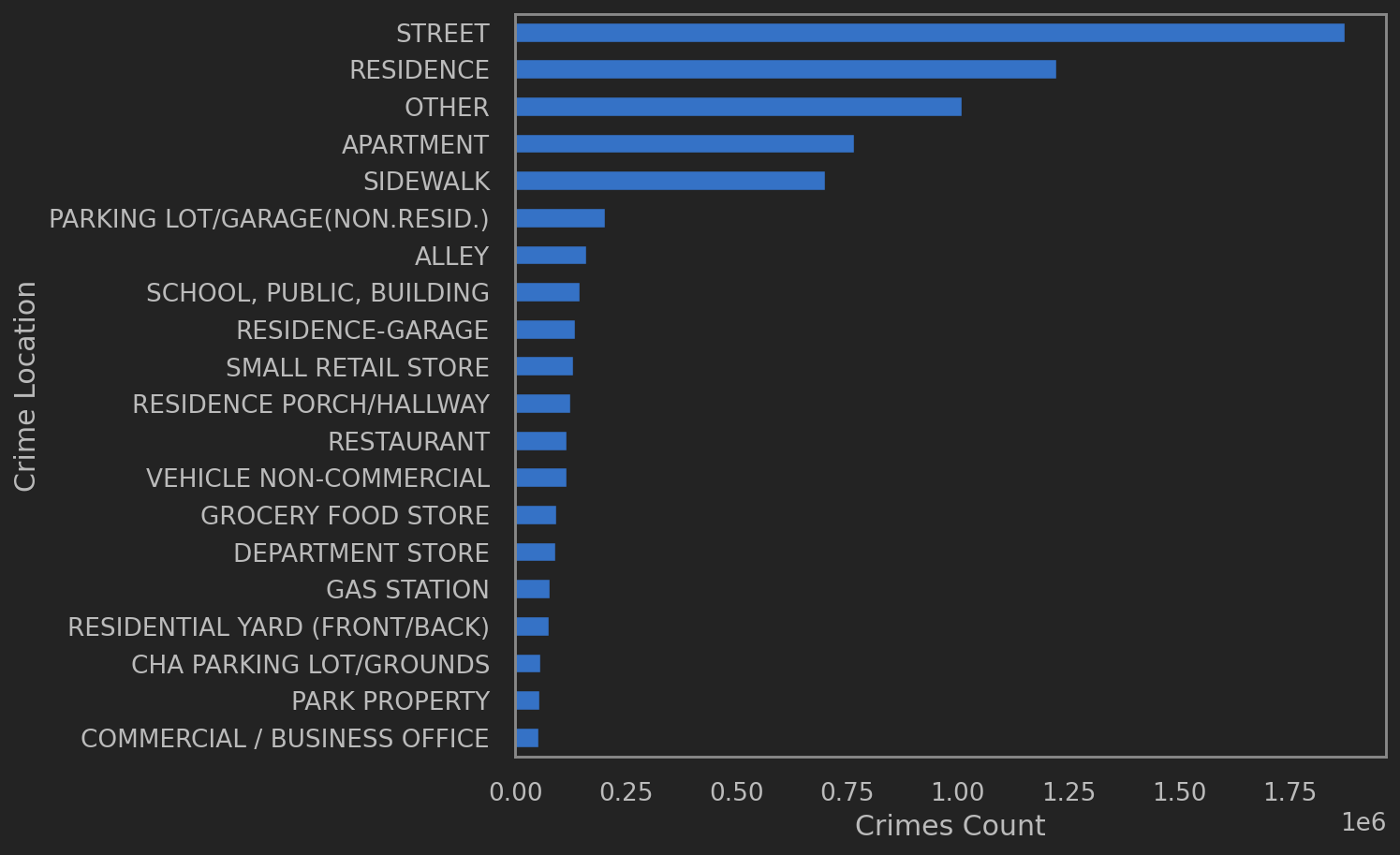
排除OTHER的话, 可以看到一下几个地点的犯罪发生率明显高于其它.
- 街道
- 居民住宅区
- 公寓
- 人行道
引入依赖包以及参考的缩放函数, 作多元的数据透视图以寻找数据联系.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from sklearn.cluster import AgglomerativeClustering as AC
def scale_df(df,axis=0):
'''
A utility function to scale numerical values (z-scale) to have a mean of zero
and a unit variance.
'''
return (df - df.mean(axis=axis)) / df.std(axis=axis)
def plot_hmap(df, ix=None, cmap='seismic', xColumn=False):
'''
A function to plot heatmaps that show temporal patterns
'''
if ix is None:
ix = np.arange(df.shape[0])
plt.imshow(df.iloc[ix,:], cmap=cmap)
plt.colorbar(fraction=0.03)
plt.yticks(np.arange(df.shape[0]), df.index[ix])
if(xColumn):
plt.xticks(np.arange(df.shape[1]), df.columns, rotation='vertical')
else:
plt.xticks(np.arange(df.shape[1]))
plt.grid(False)
plt.show()
def scale_and_plot(df, ix = None, xCol=False):
'''
A wrapper function to calculate the scaled values within each row of df and plot_hmap
'''
df_marginal_scaled = scale_df(df.T).T
if ix is None:
ix = AC(4).fit(df_marginal_scaled).labels_.argsort() # a trick to make better heatmaps
cap = np.min([np.max(df_marginal_scaled.to_numpy()), np.abs(np.min(df_marginal_scaled.to_numpy()))])
df_marginal_scaled = np.clip(df_marginal_scaled, -1*cap, cap)
plot_hmap(df_marginal_scaled, ix=ix, xColumn=xCol)
- 犯罪发生具体时间 与 位置
- 犯罪发生具体时间 与 犯罪类型
- 工作日/周末 与 位置
- 工作日/周末 与 犯罪类型
- 位置 与 犯罪类型
1
2
3
4
5
hour_by_location = fullData.pivot_table(values='ID', index='Location Description', columns=fullData.index.hour, aggfunc=np.size).fillna(0)
hour_by_type = fullData.pivot_table(values='ID', index='Primary Type', columns=fullData.index.hour, aggfunc=np.size).fillna(0)
dayofweek_by_location = fullData.pivot_table(values='ID', index='Location Description', columns=fullData.index.dayofweek, aggfunc=np.size).fillna(0)
dayofweek_by_type = fullData.pivot_table(values='ID', index='Primary Type', columns=fullData.index.dayofweek, aggfunc=np.size).fillna(0)
location_by_type = fullData.pivot_table(values='ID', index='Location Description', columns='Primary Type', aggfunc=np.size).fillna(0)
1
scale_and_plot(hour_by_location)
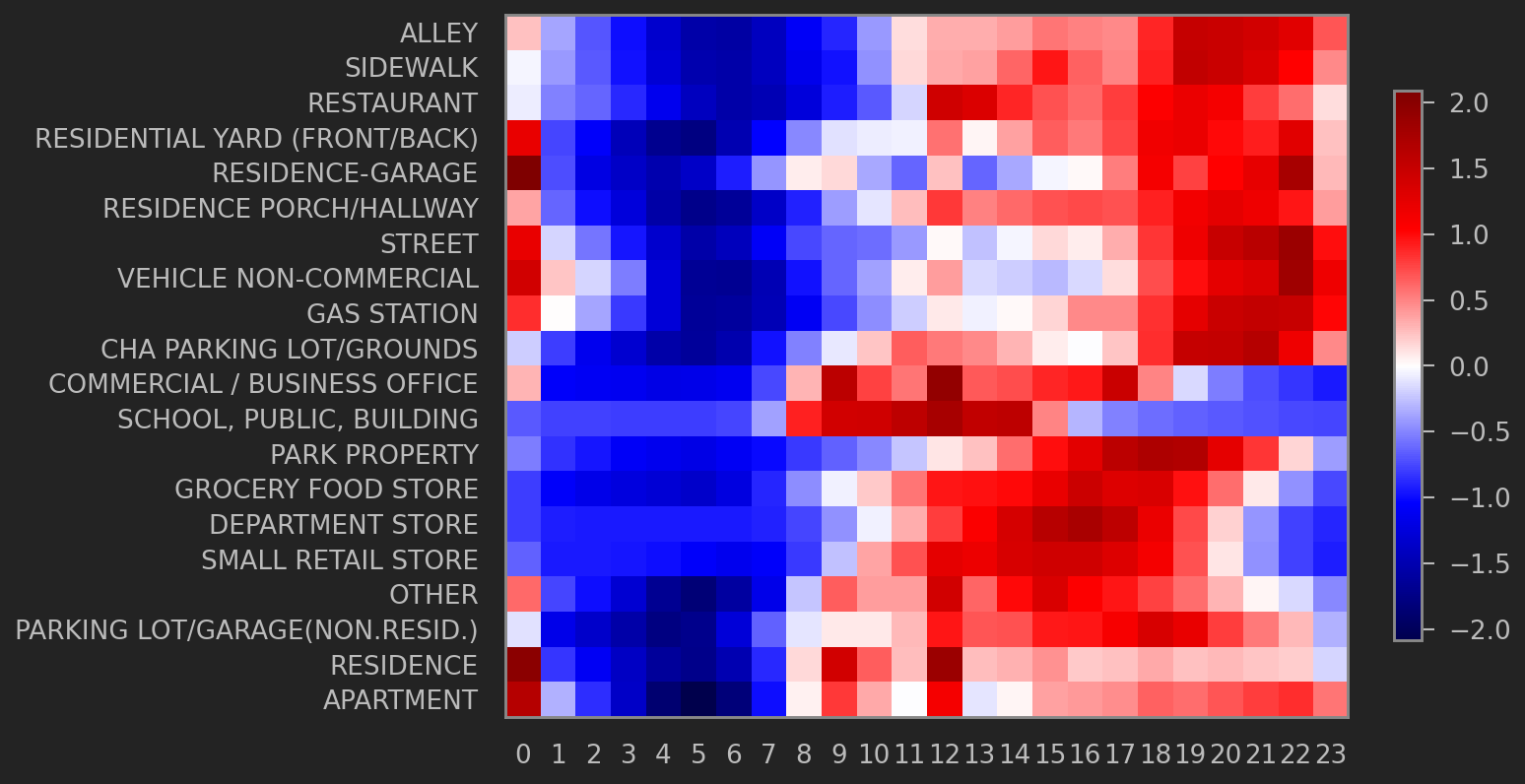
观察到有几块热区
小巷(ALLEY), 人行道(SIDEWALK), 街道(STREET), 私家车(VEHICLE NON-COM..), 加油站(GAS STATION), 停车场/区(..PARKING LOT..)区域, 都于17点过后至午夜1点犯罪活跃.
停车场(PARKING LOT..),写字楼/商业区(COMMERCIAL/BUSINESS OFFICE),学校/公共类楼宇(SCHOOL, PUBLIC BUILDING)均于早上8点至下午3点犯罪活跃.
几类商店(.. STORE)均于整个中午和下午犯罪活跃.
居民住宅区和公寓型住宅均于 正午12点与午夜0点有热区
凌晨2-6时均为冷区. 这些结论也基本与常识理解较为贴近.
1
scale_and_plot(hour_by_type)
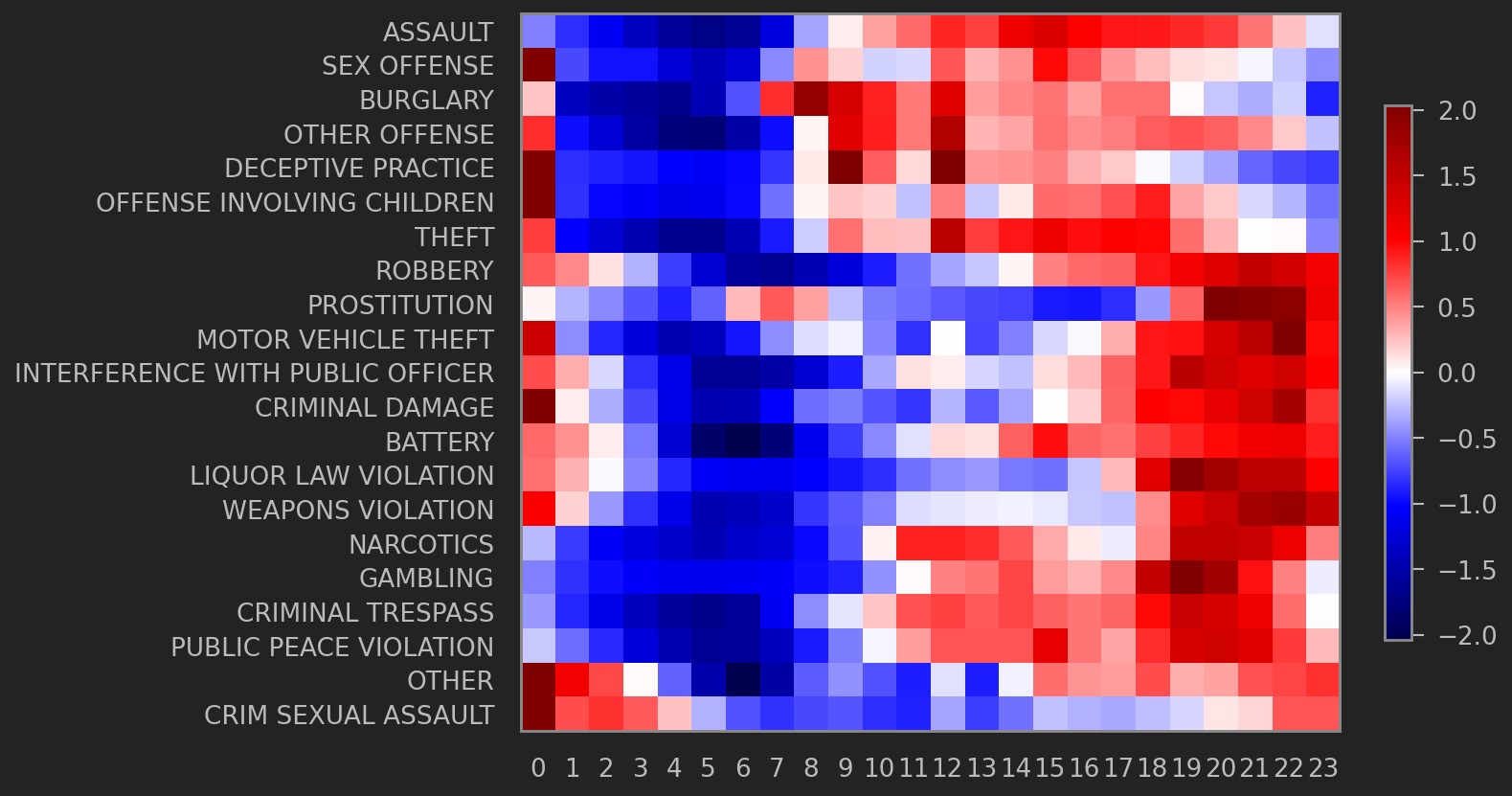
人身侵犯, 性侵犯在中午过后几小时有热区
诈骗, 欺凌类型犯罪在上午和中午有热区
其余犯罪均在18点过后, 即非工作时间存在热区.
1
scale_and_plot(dayofweek_by_location)

工作日热区:
- 停车场, 写字楼, 商店, 学校
周五/周六热区:
- 小巷, 人行道, 餐厅, 商业区停车场, 街道, 私家车, 住宅区, 住宅区走廊/门廊.
周六周日热区:
- 公寓, 油站, 住宅前/后院
1
scale_and_plot(dayofweek_by_type)
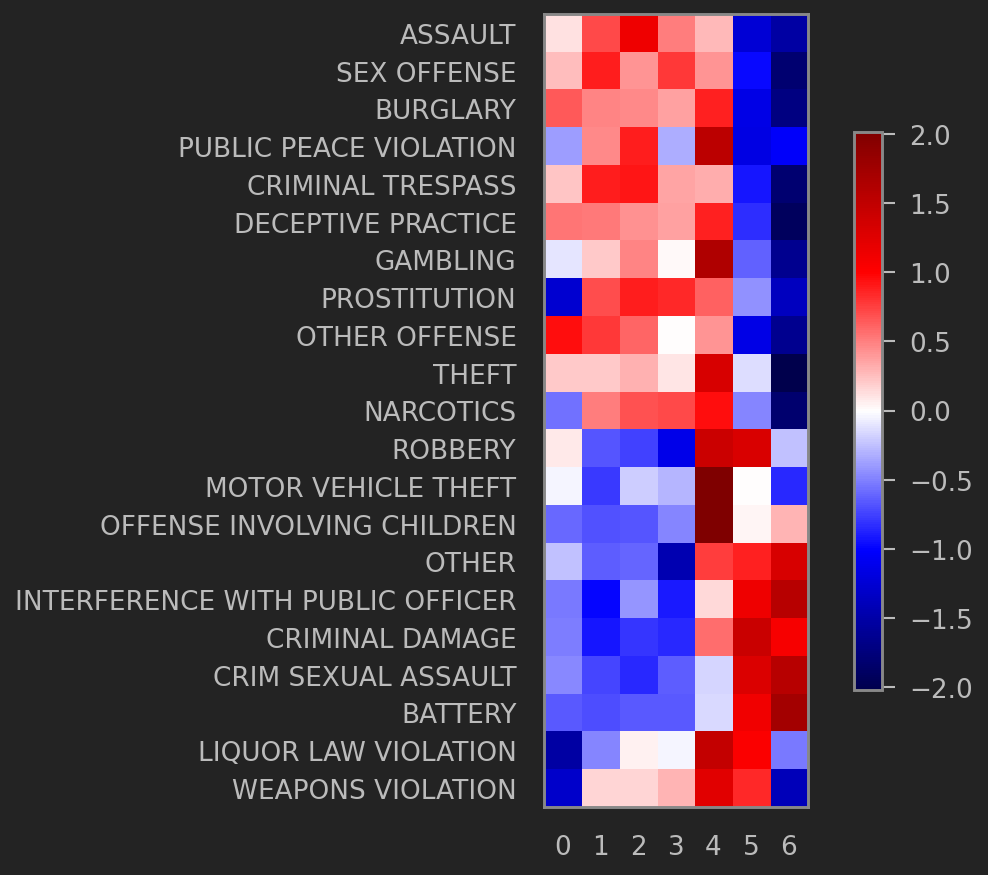
工作日热区:
人身侵犯
性骚扰
欺凌
非法入侵
卖淫
节假日热区:
妨碍公务
破坏(刑事破坏)
性侵犯
殴打/斗殴
值得注意的是, 周五当天有几个明显的热区
赌博
妨碍公共安全秩序
偷窃机动车
青少年犯罪
酒水买卖犯罪
枪械犯罪
1
scale_and_plot(location_by_type, xCol=True)
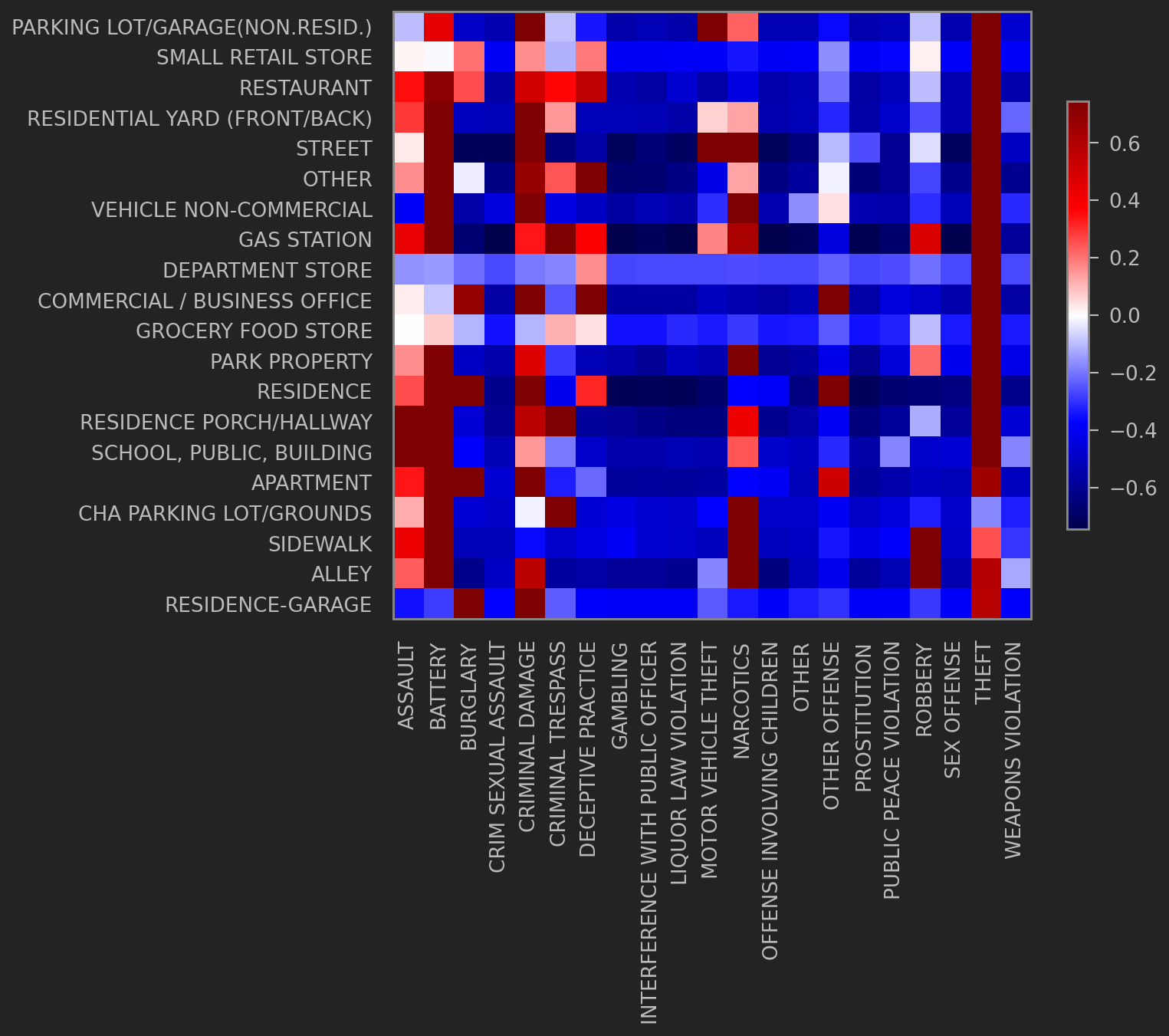
这个犯罪地点X犯罪类型的图, 每个交叉的热点都是某种特定的犯罪形式最可能发生的地点, 这里不做赘述.
只提两个点.
斗殴和盗窃在所有地点都几乎是热区
加油站地点, 几乎无赌博, 性侵, 卖淫, 酒水买卖犯罪